CPU vs GPU FP4 GEMM at Small Model Shapes
A Ryzen 9 9950X3D can beat an RTX PRO 6000 Blackwell on tiny KV projections. Then the GPU takes over by hundreds of times once the projection becomes a real MLP.
I started this as a straightforward question: what is the state-of-the-art FP4 matrix multiply path on this workstation? The obvious dense GEMM answer is not subtle. An RTX PRO 6000 Blackwell running the available SM120 FP4 kernels can push over a petaflop per second on large batched shapes. A Zen 5 desktop CPU cannot compete with that.
But that is the wrong question for decode. In small 1-8B language models, many per-token operations are skinny matrix-vector or tiny matrix-matrix projections: attention Q/K/V/O, dense MLP up/down, and, in MoEs, per-expert MLPs that may only see a few routed tokens. If the batch is small enough, kernel launch, packing, and GPU fixed costs can dominate the arithmetic.
So I ran two sweeps. First, a controlled same-shape CPU-vs-GPU sweep across representative GEMM/GEMV shapes. Second, a model-derived sweep from Hugging Face configs for Qwen2.5 1.5B/3B/7B, Mistral 7B, OLMoE-1B-7B, and Qwen1.5-MoE-A2.7B. The code and setup guide are in github.com/Infatoshi/cpu-gemm-gemv.
Important caveat: the CPU path here is true MXFP4 through ik_llama.cpp. The broadly runnable SM120 GPU path available on this machine is NVFP4/block-scaled FP4 through FlashInfer CUTLASS and b12x. The sweep is shape-matched, not format-identical.
Hardware: Ryzen 9 9950X3D, RTX PRO 6000 Blackwell Workstation Edition, CUDA 13.2 driver stack. GPU timings use CUDA events, warmups, repeated samples, and L2 flushes. CPU timings use repeated ggml/ik_llama perf runs.
The large-shape baseline
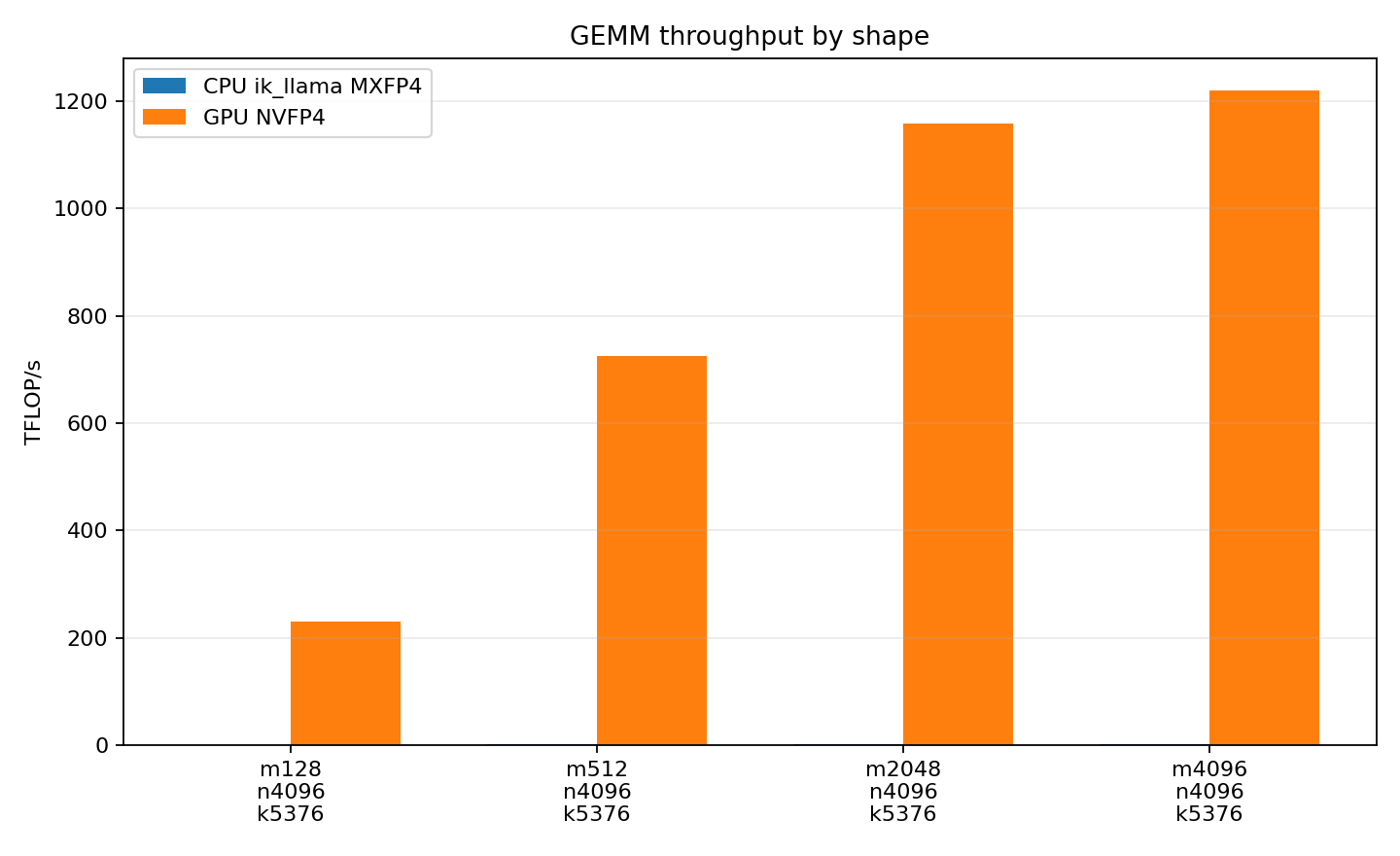
On dense GEMM, the GPU does exactly what you expect. AtM=4096,N=4096,K=5376b12x NVFP4 measured 1219 TFLOP/s. The best CPU MXFP4 path measured 2.12 TFLOP/s on the same shape. That is a 576x gap.
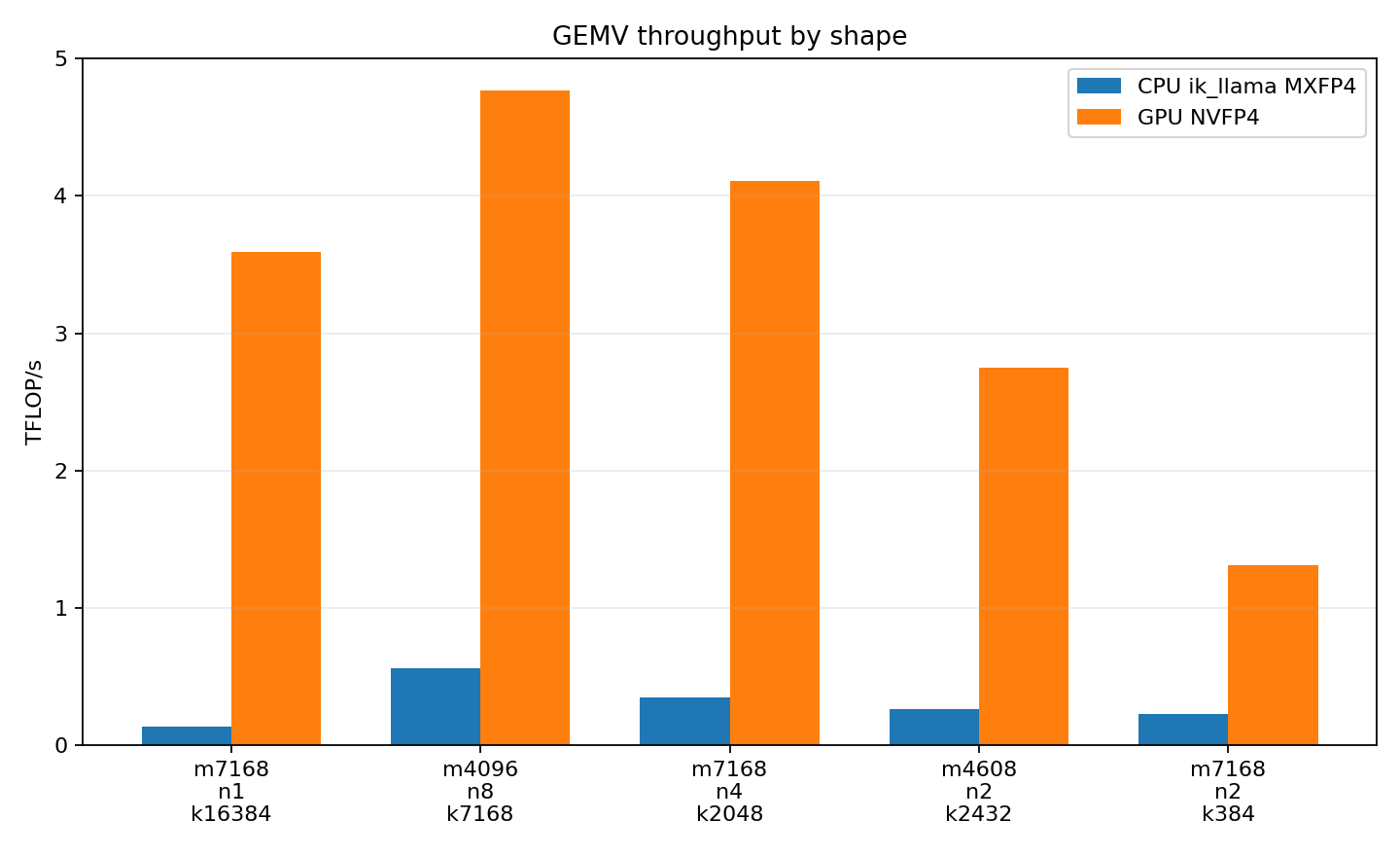
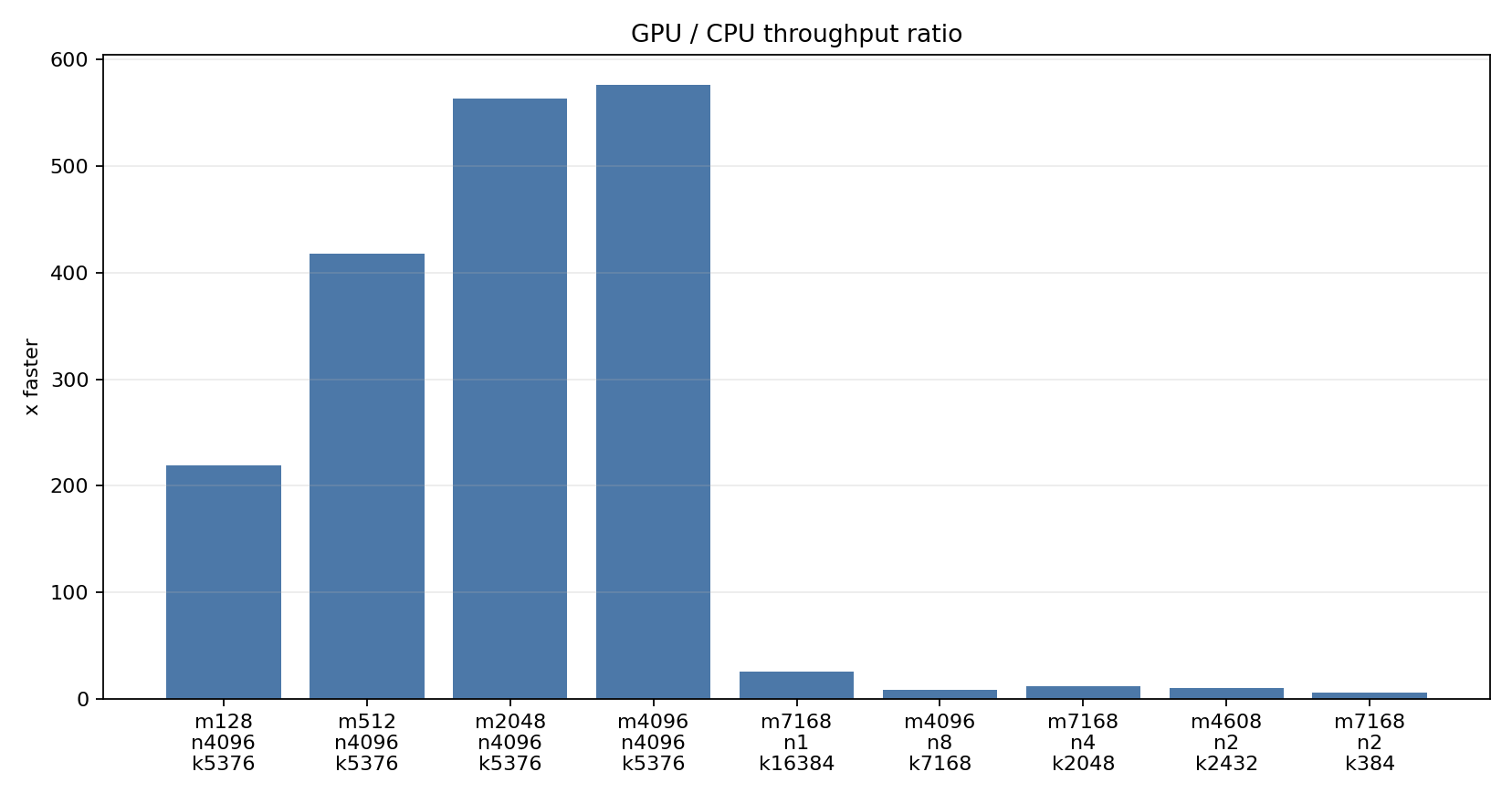
The GEMV-like shapes are less extreme but still usually favor the GPU. The GPU wins by 5.8x to 25.9x in this hand-picked set. That already suggests a boundary: for projection sizes in the thousands and a few tokens, the CPU is not absurdly far away.
Deriving real model shapes
I pulled public config.jsonfiles and derived the projection shapes. For dense models this means: attention Q, KV, fused QKV, O, MLP up/gate, and MLP down. For MoE models, I also derived average per-expert token counts fromtokens * top_k / num_experts, rounded up, plus shared-expert projections where the config has them.
| Model | Hidden | MLP / Expert | MoE |
|---|---|---|---|
| Qwen2.5-1.5B | 1536 | 8960 | dense |
| Qwen2.5-3B | 2048 | 11008 | dense |
| Qwen2.5-7B | 3584 | 18944 | dense |
| Mistral-7B-v0.3 | 4096 | 14336 | dense |
| OLMoE-1B-7B | 2048 | 1024 expert | 64 experts, top-8 |
| Qwen1.5-MoE-A2.7B | 2048 | 1408 expert, 5632 shared | 60 experts, top-4 |
Where the crossover appears
The model-derived sweep is the interesting one. At one token, the median GPU/CPU speedup is only 5.4x. The minimum is 0.6x, meaning the CPU wins. At two tokens, the minimum is still only 0.7x. By eight tokens the GPU wins every shape in the sweep, but the median is still just 10.9x. By 128 tokens, the median jumps to 46.6x and the best MLP case reaches 259x.
source tokens | median GPU/CPU | min | max
────────────────────────────────────────
1 | 5.4x | 0.6x | 24.7x
2 | 5.9x | 0.7x | 26.4x
4 | 7.2x | 0.8x | 33.5x
8 | 10.9x | 1.2x | 54.4x
128 | 46.6x | 5.5x | 259.3x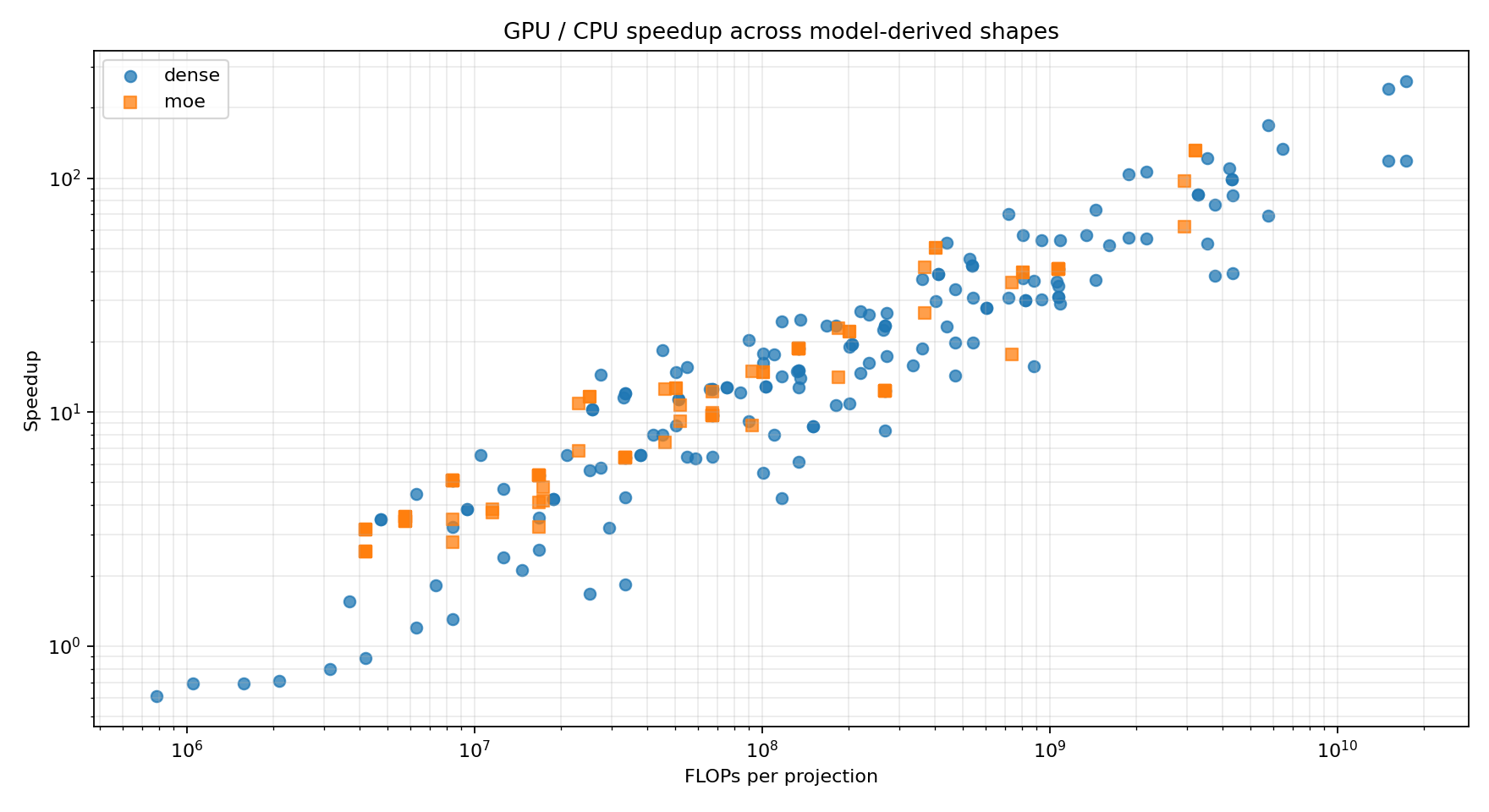
The CPU actually beats the GPU on Qwen2.5's tiny KV projections:
model op tokens M N K GPU TF/s CPU TF/s
────────────────────────────────────────────────────────────────────
Qwen2.5-1.5B attn_kv_each 1 1 256 1536 0.074 0.122
Qwen2.5-1.5B attn_kv_each 2 2 256 1536 0.159 0.231
Qwen2.5-3B attn_kv_each 1 1 256 2048 0.088 0.127
Qwen2.5-3B attn_kv_each 2 2 256 2048 0.168 0.236That does not mean “run the transformer on the CPU.” It means that for small decode, a projection-by-projection runtime has a lot of overhead hiding under the FLOP/s headline. A CPU kernel with no device launch and no packing pipeline can be competitive on the tiniest shapes.
Dense models: attention vs MLP
Dense attention projections are mixed. Q and O are square-ish and become GPU-friendly with enough tokens. KV projections in grouped-query models can be very skinny. MLPs, on the other hand, quickly become classic large GEMMs.
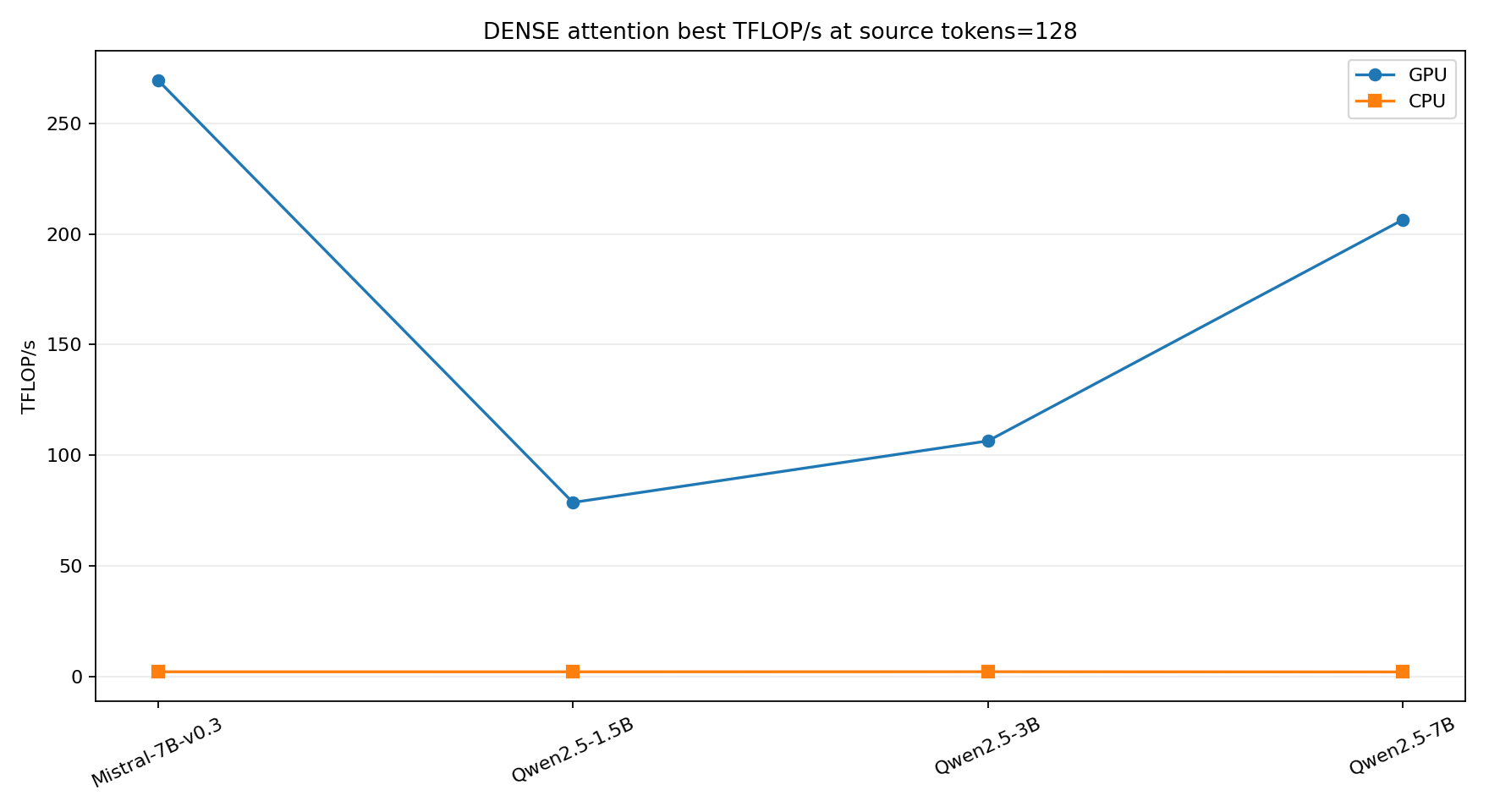
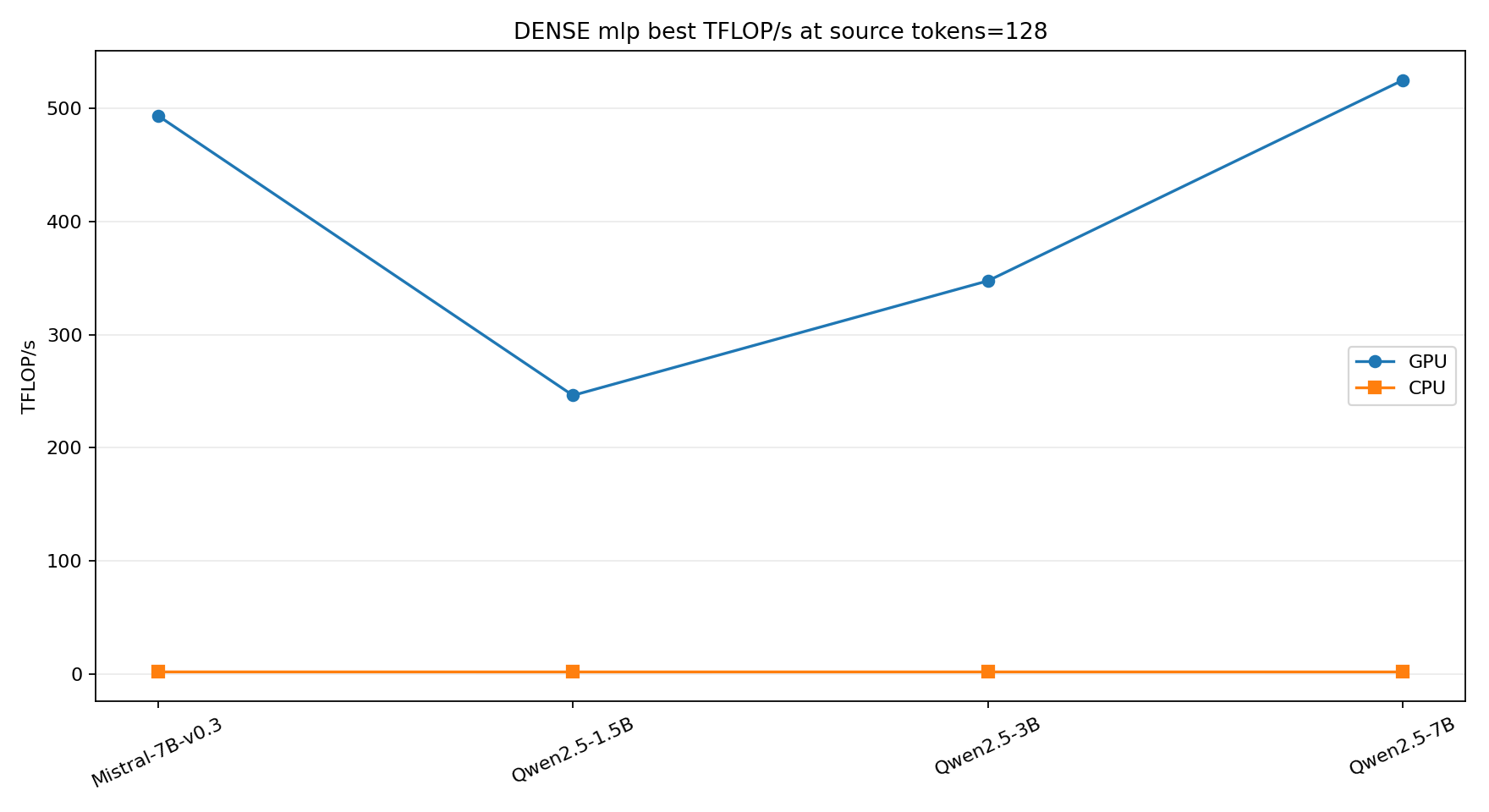
MoE makes the small-shape problem worse
MoE expert routing shrinks the per-expert matrix shape. OLMoE has 64 experts and top-8 routing, so with one source token the average expert seesceil(1 * 8 / 64) = 1token. Qwen1.5-MoE has 60 experts and top-4 routing, so it stays around one token per expert until the source batch grows substantially. This is the regime where GPU utilization is easiest to lose.
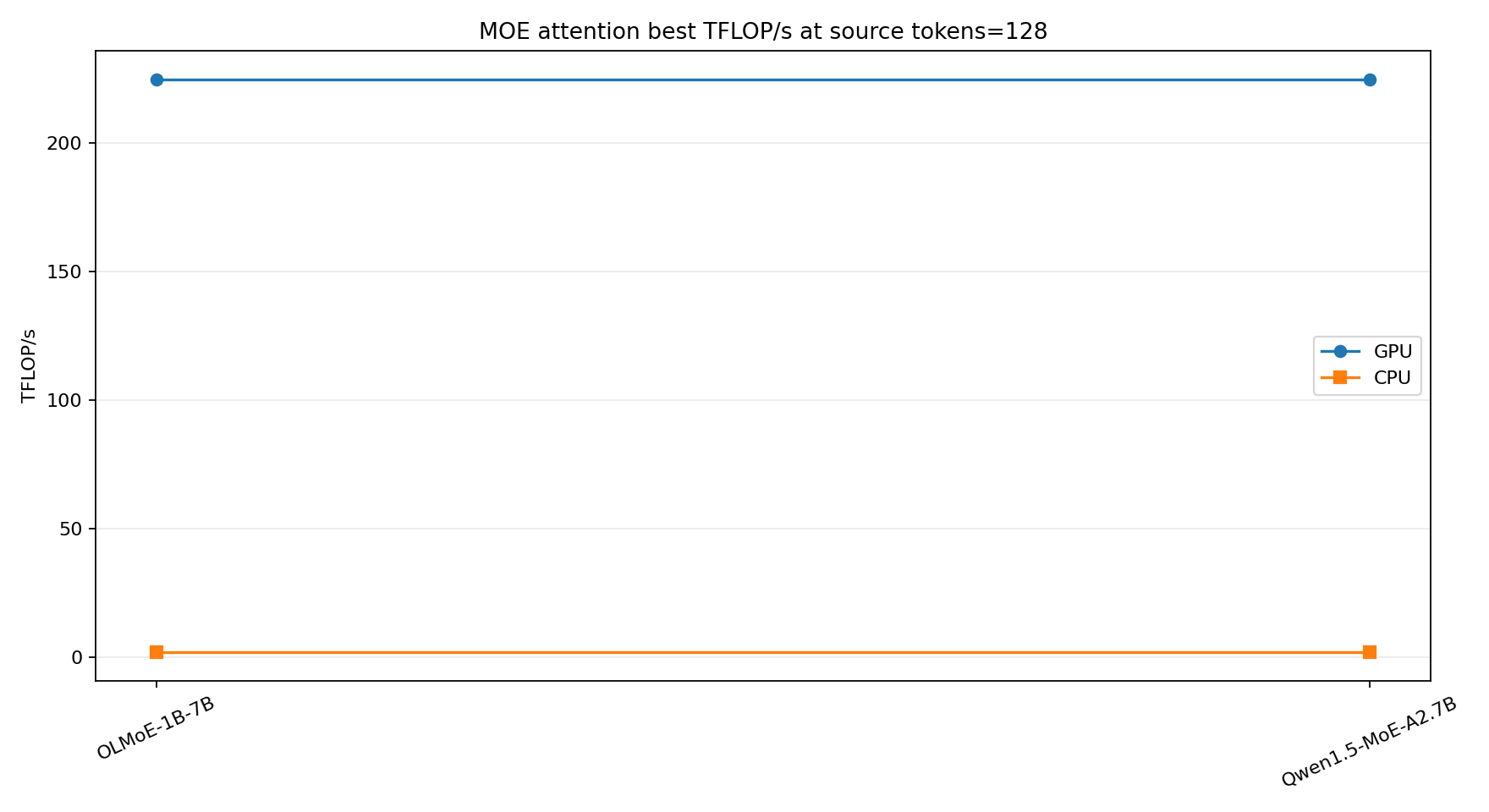
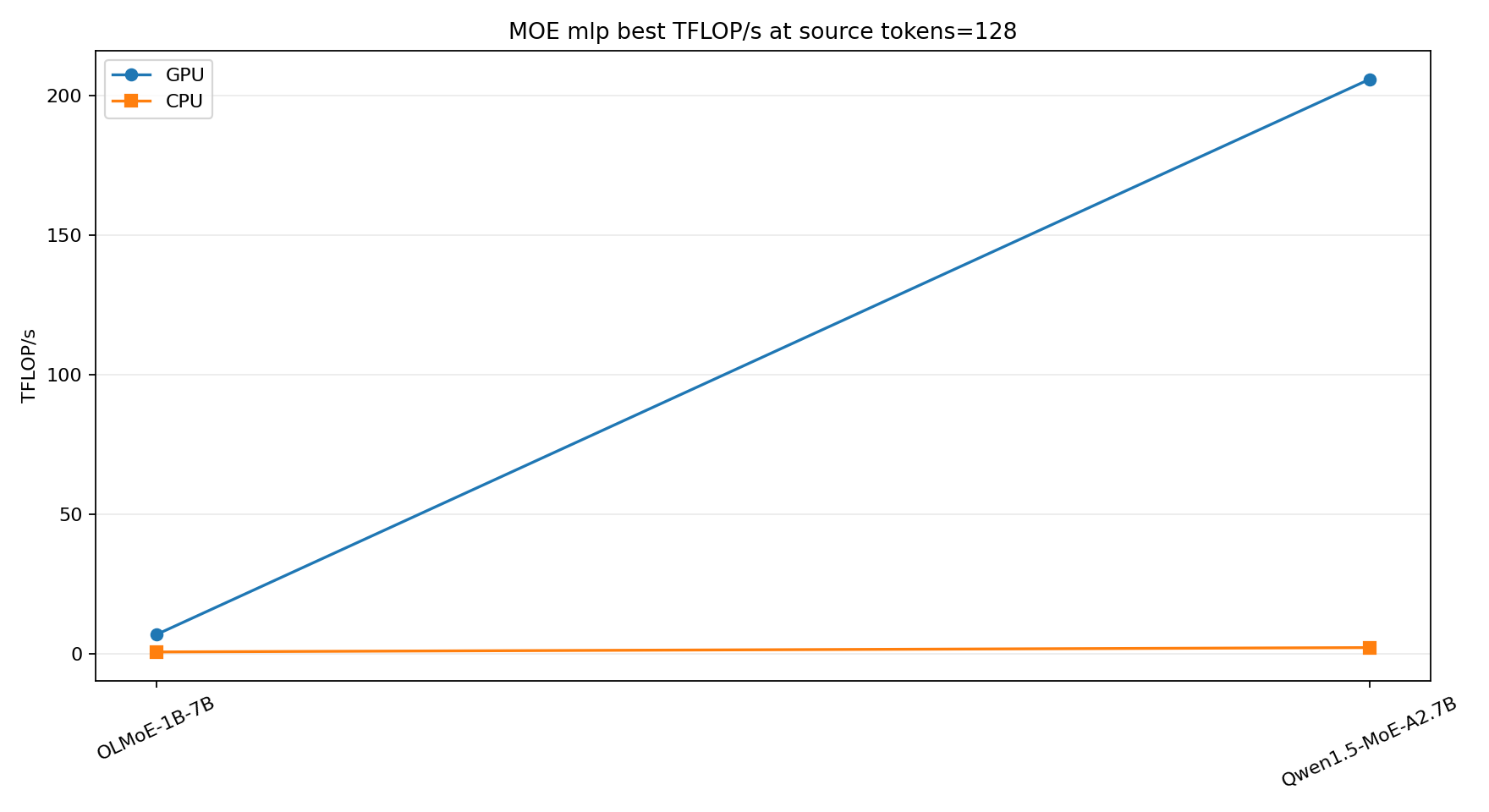
What I would take away
- Dense MLPs belong on the GPU. Even at modest token counts, they turn into enough work to amortize GPU fixed costs.
- Tiny KV and per-expert MoE projections are different. At one or two routed tokens, the CPU can be within the same order of magnitude and occasionally faster in this benchmark setup.
- The useful boundary is shape-specific. A runtime that blindly treats every projection as a GEMM misses the small-shape regime.
- Format parity still matters. I want a packaged SM120 MXFP4 GEMV path before treating this as a final architectural result.
The practical next experiment is not “CPU vs GPU” in the abstract. It is a scheduler: keep large MLPs and batched QKV on the GPU, but consider CPU execution or CPU-assisted packing for the smallest KV/expert projections during low-batch decode. That is where the result points.
Reproducibility
The standalone repo includes the sweep scripts, setup notes, result schema, and instructions for building the CPU benchmark harness:
git clone https://github.com/Infatoshi/cpu-gemm-gemv
cd cpu-gemm-gemv
uv run --no-project --python /home/infatoshi/cpu/.venv/bin/python \
python scripts/run_model_shape_sweep.py --out-dir results/model_shape_sweepRaw result JSON is also mirrored with this post:controlled sweep and model-shape sweep.