Driftin: Single-Step Image Generation at 306 FPS
What if you could generate images in one forward pass instead of fifty? Same UNet, same parameters, 57x faster. Here's what we found when we actually built it and benchmarked it on a 3090.
git clone https://github.com/infatoshi/driftin.git
cd driftin
# Train DDPM baseline (50k steps, ~2h on 3090)
python -m drifting_vs_diffusion.train_ddpm
# Train Drifting with DINOv2 features (50k steps, ~2.5h on 3090)
python -m drifting_vs_diffusion.train_drift --encoder dinov2 --use-features
# Multi-GPU (this is where drifting really shines -- bigger batch = better signal)
torchrun --nproc_per_node=8 -m drifting_vs_diffusion.train_drift_ddp \
--encoder dinov2 --batch-size 512 --steps 50000
# Benchmark inference
python bench_inference_full.py
The Speed Gap
We benchmarked both methods on the same 38M-parameter UNet on a single RTX 3090:
| Method | Steps | Latency (1 image) | FPS |
|---|---|---|---|
| DDPM (DDIM sampling) | 50 | 418 ms | 2.4 |
| Drifting | 1 | 3.26 ms | 306 |
That's not a typo. 306 frames per second for image generation on a consumer GPU, with torch.compile and zero other optimization. No TensorRT, no quantization, no custom kernels. Just one forward pass.
At batch size 128, drifting pushes 1,574 images per second on a single 3090.
Why This Makes Real-Time Video Generation Feasible
Every video diffusion model today -- Sora, Kling, Runway -- generates frames through iterative denoising. Each frame requires hundreds of sequential neural network evaluations. Real-time? Impossible. Interactive? Forget it.
Drifting changes this. One forward pass per frame. On a 3090:
| Resolution | Latency | FPS | Notes |
|---|---|---|---|
| 32x32 | 3.3 ms | 306 | Current experiments |
| 64x64 | ~6 ms | ~160 | Extrapolated |
| 64x64 latent → 512x512 | ~13 ms | ~77 | With VAE decoder |
For latent-space generation (like Stable Diffusion's architecture), drifting in 64x64 latent space + VAE decode to 512x512 could hit 77 FPS on a single consumer 3090. On an H100, that's 150+. This is real-time territory.
And we haven't even touched TensorRT, INT8 quantization, or CUDA graphs yet. With those, sub-millisecond generation at 32x32 is within reach.
How Drifting Works
Instead of learning to predict noise (diffusion), drifting learns to map noise directly to images in one shot. During training:
- Generate images from noise via the UNet (single forward pass)
- Extract features from both generated and real images using a frozen encoder (DINOv2)
- Compute a drift field -- a weighted direction in feature space that pushes generated features toward real data, using a softmax kernel over pairwise distances
- Train the UNet so its output follows the drift field
At inference time, the feature encoder is not needed. It's just: noise → UNet → image. One pass.
The critical insight is that drift field quality is proportional to how many samples participate in the kernel estimation. More samples = better estimate of where real data lives in feature space = stronger learning signal.
- 1 GPU, batch size 128: weak drift signal, blobby results
- 8 GPUs, batch size 4096: scene-like compositions
- Hypothetical 1000 GPUs, batch size 500k: potentially state-of-the-art
This is the opposite of diffusion, where batch size mainly affects gradient noise. For drifting, batch size IS the signal. This means drifting is uniquely suited to massive-scale training -- the kind of compute that companies already deploy for video models. You train big, you serve small.
The Experiments: 8x H100s, One Night
We ran five experiments on an 8x H100 node, comparing DDPM against drifting with different feature encoders:

DDPM (top, blue): Sharp, detailed CIFAR-10 images after 50k training steps.
Drift + ResNet-18 (middle, orange): Blurry but scene-like compositions. ResNet-18's 128D features provide a weak drift signal.
Drift + DINOv2 (bottom, green): Dramatic improvement. Recognizable animals, vehicles, landscapes. DINOv2's 768D self-supervised features provide exactly the visual nearest-neighbor signal the drift kernel needs.
Feature Encoder Quality > Batch Size
The most surprising finding: DINOv2 with a 4x smaller batch (1024) produced better images than ResNet-18 with a 4x larger batch (4096). And pixel-space drifting collapsed entirely:
| Encoder | Dimension | Global Batch | Quality |
|---|---|---|---|
| Pixel-space | 3072 | 4096 | Mode collapse (useless) |
| ResNet-18 | 128 | 4096 | Blobby, some scenes |
| DINOv2 | 768 | 1024 | Recognizable objects |
Pixel-space fails because of the curse of dimensionality: in 3072D, all pairwise distances concentrate around the same value. The softmax kernel becomes uniform, the drift signal vanishes. Feature-space is mandatory, and the quality of those features matters enormously.
Training Loss Curves
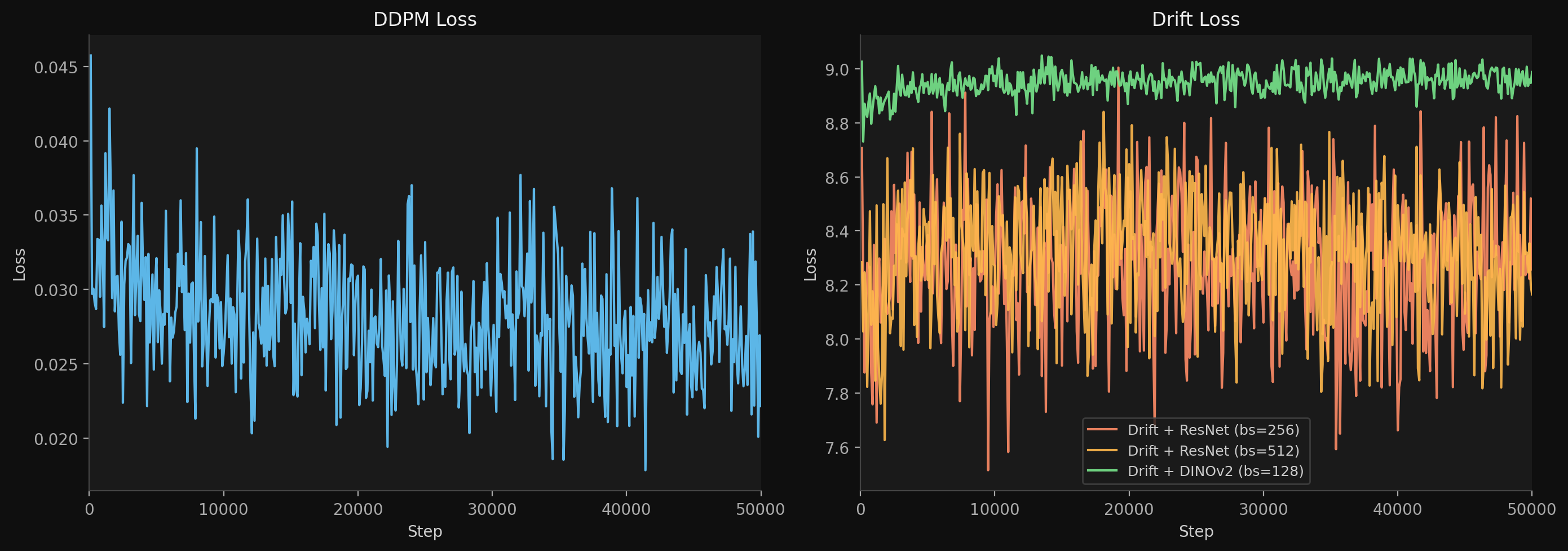
DDPM loss (left) converges cleanly from 0.045 to 0.022 over 50k steps. Drift losses (right) are noisy and flat by design -- the drift normalization (lambda_j) rescales V to unit per-dimension variance, so the absolute loss value is not a convergence metric. The actual signal is in sample quality, not the loss curve. DINOv2 sits highest (~9.0) because its 768D features produce stronger drift signals.
Batch Generation
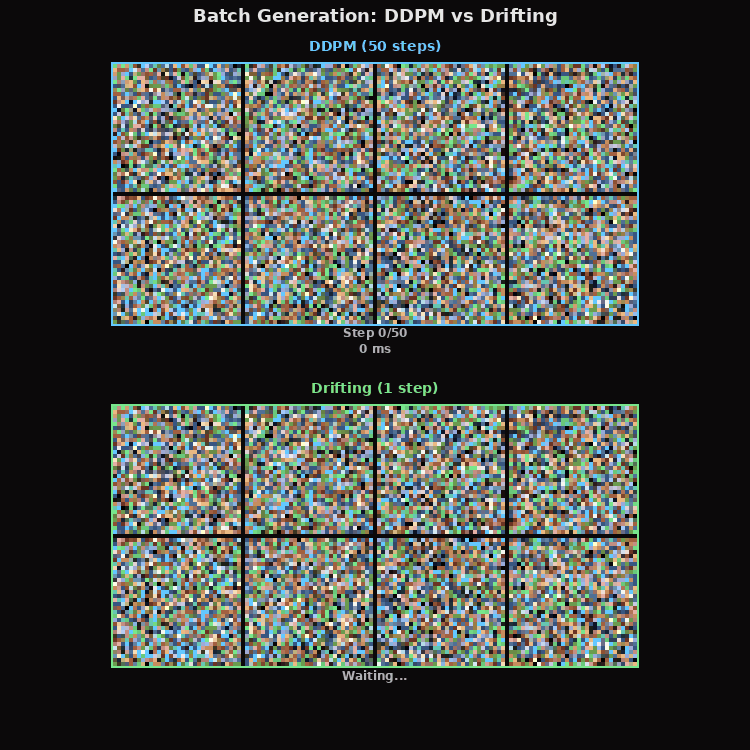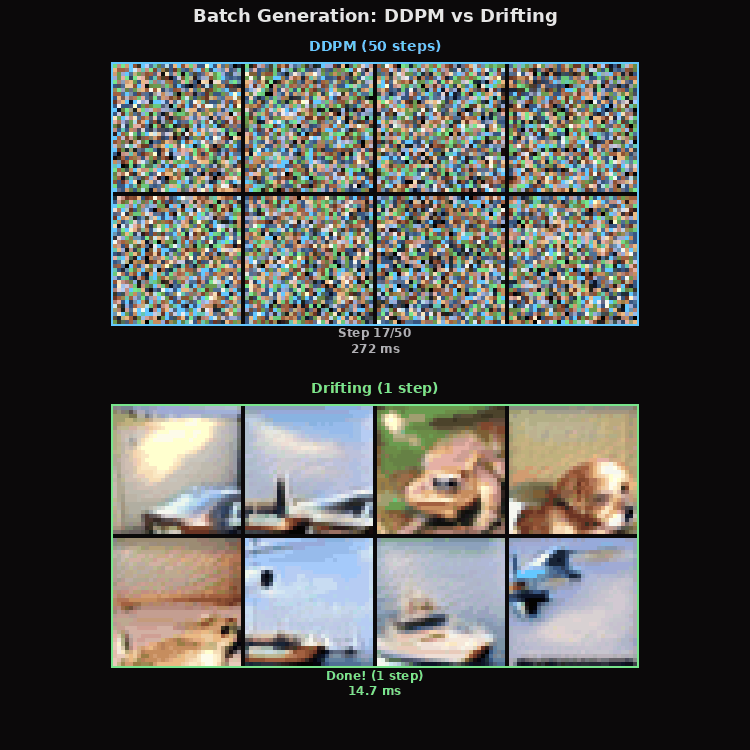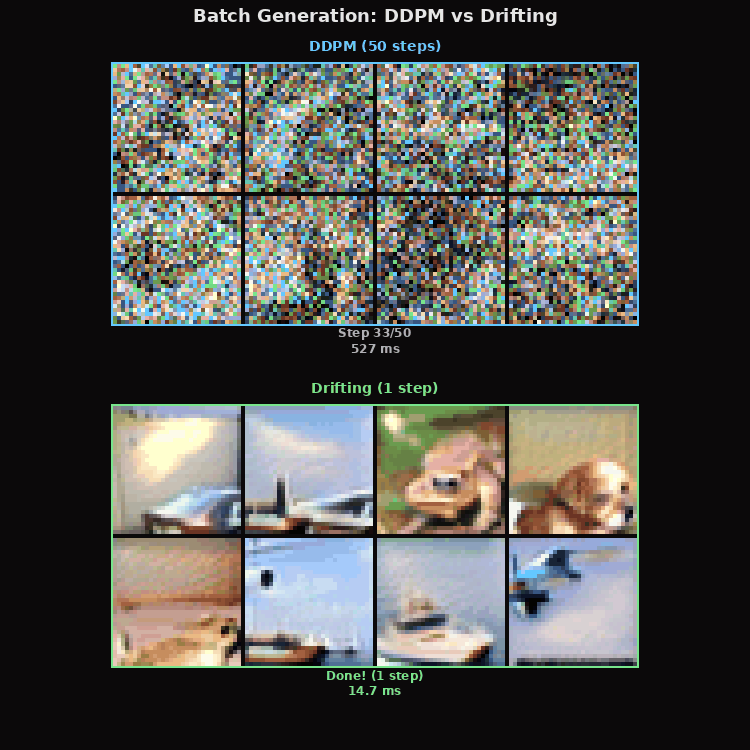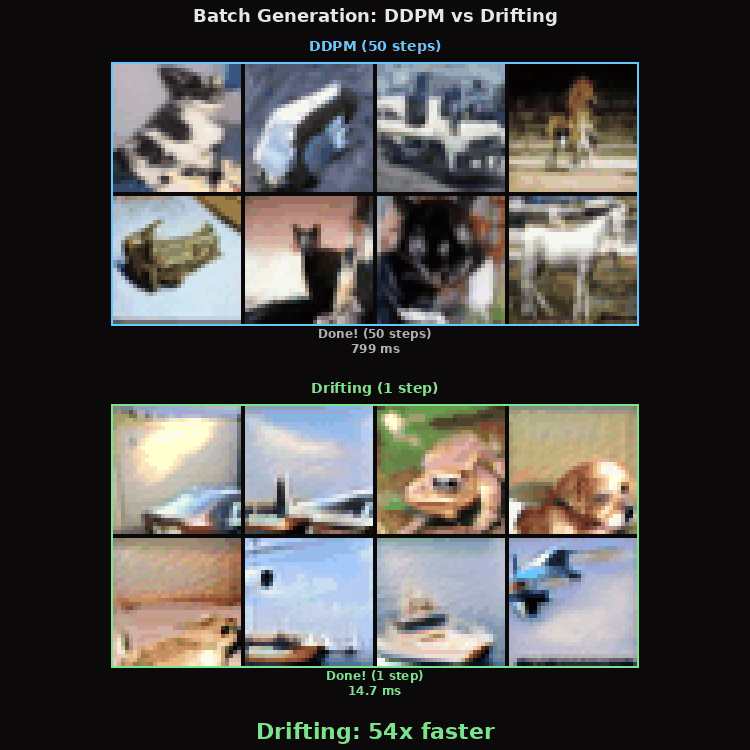
8 images simultaneously. Drift generates all 8 in 14.6 ms. DDPM takes 808 ms. Same UNet, same weights (approximately), 55x speed gap.
Inference Optimization Deep Dive
We benchmarked 5 optimization strategies across 8 batch sizes on the 3090, using CUDA event timing (GPU-side, not wall clock):
| Method | bs=1 | bs=8 | bs=32 | bs=128 |
|---|---|---|---|---|
| Eager bf16 | 8.59 ms | 1.84 ms/img | 1.24 ms/img | 1.08 ms/img |
| Eager fp32 | 7.22 ms | 2.02 ms/img | 1.57 ms/img | 1.42 ms/img |
| torch.compile | 3.87 ms | 1.29 ms/img | 0.81 ms/img | 0.64 ms/img |
| compile max-autotune | 3.26 ms | 1.08 ms/img | 0.75 ms/img | 0.64 ms/img |
| CUDA graphs | 6.80 ms | 1.61 ms/img | 1.21 ms/img | 1.03 ms/img |
torch.compile with max-autotune gives a 2.6x speedup over eager mode for free. The Triton autotuner selects optimal tile sizes for every convolution kernel. CUDA graphs on the eager model barely helped (~4%) because the model is compute-bound, not launch-overhead-bound.
One surprising finding: bf16 is actually slower than fp32 at batch size 1. The 3090's tensor cores need enough work to amortize the format conversion overhead. At batch size 8+, bf16 pulls ahead.
What Went Wrong Along the Way
Plenty. Some highlights from the overnight session on 8x H100s:
- CIFAR-10 download race condition in DDP. All 8 ranks tried to download simultaneously. Fixed by having rank 0 download first, then
dist.barrier(), then all ranks load. - DINOv2 non-contiguous tensors. The ViT's CLS token output isn't contiguous in memory.
dist.all_gathersilently fails. Fixed with.contiguous(). - bf16 underflow in softmax. With temperature 0.02 and high-dimensional features, the logits are so negative that bf16 can't represent them. The entire softmax becomes zero. Fixed by casting to fp32 for the distance/softmax computation.
- Drift loss is always ~1.0. Spent an hour thinking training was stuck. It's by design -- the drift normalization (lambda_j) rescales V to unit per-dimension variance. Loss value is not a convergence metric. Look at the samples.
- 210M param UNet was too slow. Built a large config to use more of the H100's 80GB. ETA was 12.5 hours for 200k steps. Killed it and went back to the small model with bigger batches -- better tradeoff for our time budget.
What's Next
The quality gap between drifting and diffusion is real. But DINOv2 features closed a huge chunk of it, and we've only trained at CIFAR-10 scale with global batch 1024. The path forward:
- Scale batch size. 1000+ GPUs, global batch 100k+. This directly improves drift signal quality.
- Better feature encoders. SigLIP, DINOv2-giant, or task-specific encoders trained for drift compatibility.
- Latent-space drifting. Operate on VAE latents instead of pixels. Enables higher resolution while keeping the drift field low-dimensional.
- Video. Condition on previous frames. At 77 FPS in latent space on a 3090, real-time AI video is within reach.
- Inference optimization. TensorRT, INT8, CUDA graphs. Push toward sub-millisecond generation.
The dream: train on 1000 GPUs for a month, serve on a single consumer GPU at 60 FPS. Diffusion fundamentally cannot do this. Drifting can.
Acknowledgments
Multi-GPU training experiments were run on 8x H100 GPUs provided by Voltage Park. Thank you for the compute sponsorship.
Code
git clone https://github.com/infatoshi/driftin.git
cd driftin
pip install torch torchvision
# Single GPU
python -m drifting_vs_diffusion.train_drift --encoder dinov2 --use-features
# Multi-GPU (more GPUs = better drift signal)
torchrun --nproc_per_node=8 -m drifting_vs_diffusion.train_drift_ddp \
--encoder dinov2 --batch-size 512 --steps 50000- GitHub: github.com/infatoshi/driftin
- Full development log with every experiment: DEVLOG.md
February 2026