Beating an All-GPU DSA Kernel by Offloading Top-K to AVX-512
One workstation, two heterogeneous compute units, and one stage of DeepSeek Sparse Attention that turns out to be in the wrong place.
The setup
DeepSeek-V3.2 introduced Sparse Attention (DSA): for each query token, a small “Lightning Indexer” scores all preceding keys with I[t,s] = Σⱼ wⱼ · ReLU(⟨qⱼ, kₛ⟩), a top-K is taken over those scores, and the main attention runs only over the selected keys. I built the whole thing from scratch on a single workstation: PyTorch reference, naive per-query Python loop, and a single fused Triton kernel that does indexer → tl.sort top-K → sparse attention in one launch. All three agree numerically.
Then I asked a slightly weirder question: the GPU does the top-K via a bitonic sort inside the kernel. What if I just send the score matrix to the CPU mid-pipeline, do the top-K there with AVX-512, and ship the threshold back? The hardware is RTX PRO 6000 Blackwell on PCIe 5.0 x16 and a Ryzen 9 9950X3D (Zen 5, 16 cores, full AVX-512). The PCIe bandwidth is real. Maybe the CPU is faster at this specific op than people assume.
First attempt: just use torch.topk on CPU
Easy answer first. Spin up torch.topk on the score tensor on the CPU side and time the round-trip against an in-kernel GPU sort. Result: CPU offload loses everywhere by 20-130×, including at a 4 GB score matrix (B=64, T=4096). Not close.
But why? PyTorch advertises CPU capability usage: AVX512 in its build config. Zen 5 has full AVX-512 with vbmi2, vp2intersect, bf16, vnni - everything. The CPU should be fast at this. So I attached perf to the hot loop.
The smoking gun
78% of CPU time was in this one symbol:
std::__introselect<pair<float, long>*, ...,
AVX2::topk_impl_loop<float, float>::{lambda...}>That's GCC's scalar introselect, partial-sorting std::pair<float, long> with a function-pointer comparator. The AVX2:: namespace is just where Torch placed the dispatch - the inner loop is pure scalar comparison. The pair is 16 bytes (4 + padding + 8) so half the memory bandwidth is wasted on the index. Another 13% was in gomp_team_barrier_wait_end, i.e. OpenMP overhead from too-fine parallel granularity.
The PyTorch CPU top-K kernel is not using AVX-512 at all. It is template-instantiated scalar code that happens to live inside a namespace named after a vector ISA. Worth knowing.
Writing a real AVX-512 top-K
For DSA we don't actually need the indices, just the threshold value (the k-th largest per row, which we then compare against the score matrix to build the selection mask). That simplifies the kernel a lot. Per row:
- Maintain a descending-sorted buffer of size k, initialized to -∞.
- Load 16 floats with
_mm512_loadu_ps. - Compare against the current threshold (= last element of the buffer) with
_mm512_cmp_ps_mask. If the mask is zero, skip the chunk. This is the common case once the buffer warms up. - Otherwise compress-store only the candidates with
_mm512_mask_compressstoreu_psand scalar-insert each into the sorted buffer.
Parallelize rows with OpenMP, compile with -march=native -mavx512f -mavx512vbmi2 -fopenmp, JIT-load through torch.utils.cpp_extension.load. The first pass was a small sorted-buffer kernel. The final version keeps that path for k ≤ 32, then switches larger k to a min-heap so each accepted candidate costs O(log k) instead of shifting an O(k) buffer.
CPU top-K alone: AVX-512 vs torch.topk
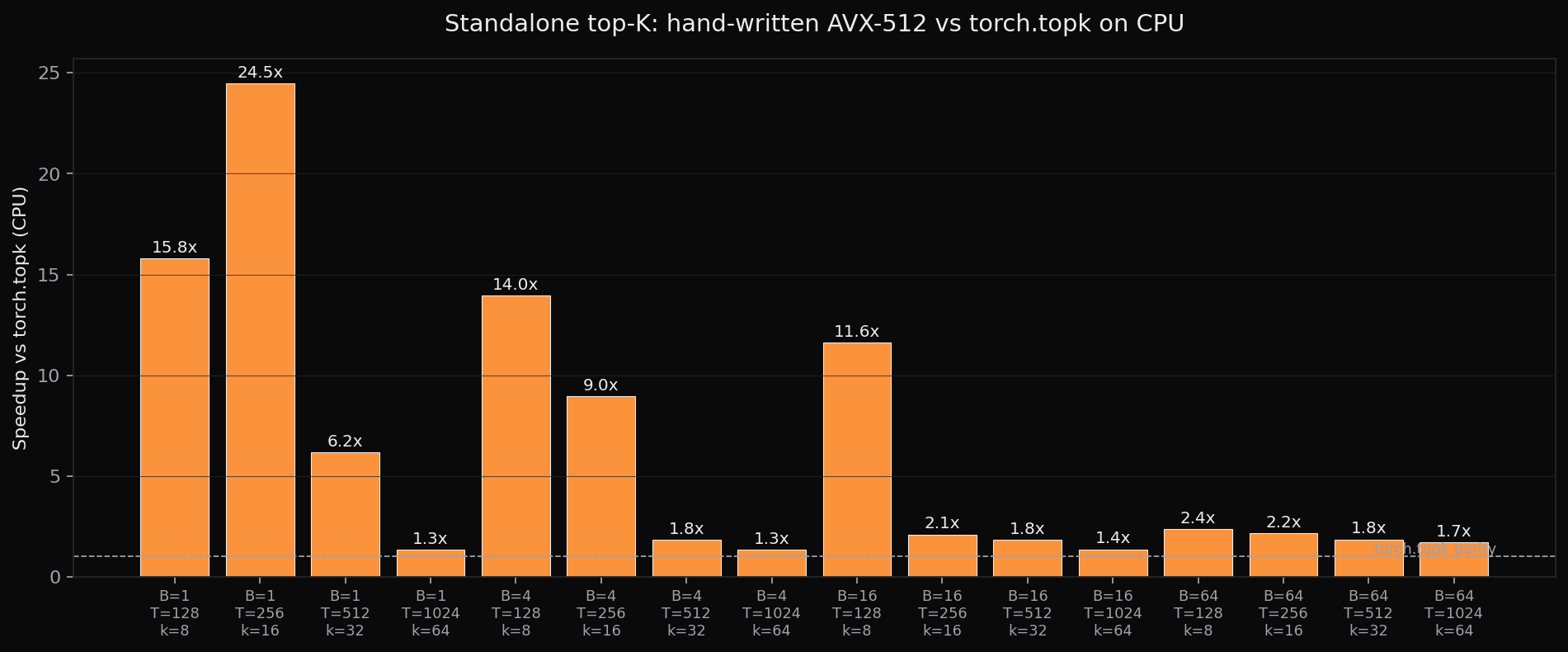
B T k | torch (ms) avx512 (ms) speedup
─────────────────────────────────────────────────
1 128 8 | 0.069 0.004 15.8x
1 256 16 | 0.197 0.008 24.5x
4 128 8 | 0.209 0.015 14.0x
16 1024 64 | 8.461 6.221 1.4x
64 1024 64 | 42.4 24.9 1.7xBeats torch.topk in 17 of 20 shapes, by 1.3× to 34× in the first benchmark pass. The win shrinks as k grows, which is why the later kernel keeps a sorted buffer only for small k and uses a heap for k=64/128.
The actual experiment: hybrid pipeline end-to-end
Standalone CPU wins are nice but the question I cared about was: does this beat the all-GPU fused DSA kernel end-to-end? Pipeline on the hybrid path:
- GPU: indexer scores [B, T, T]
- Pinned d2h: scores → CPU
- CPU: AVX-512 k-th-largest → threshold [B, T]
- Pinned h2d: threshold → GPU
- GPU: sparse-attention kernel that takes the precomputed threshold (no in-kernel sort)
Versus the all-GPU baseline that does indexer → tl.sort → sparse attention in one launch. Both produce bit-identical outputs at every shape tested except one tied-cluster case at 7.6e-2 abs diff.
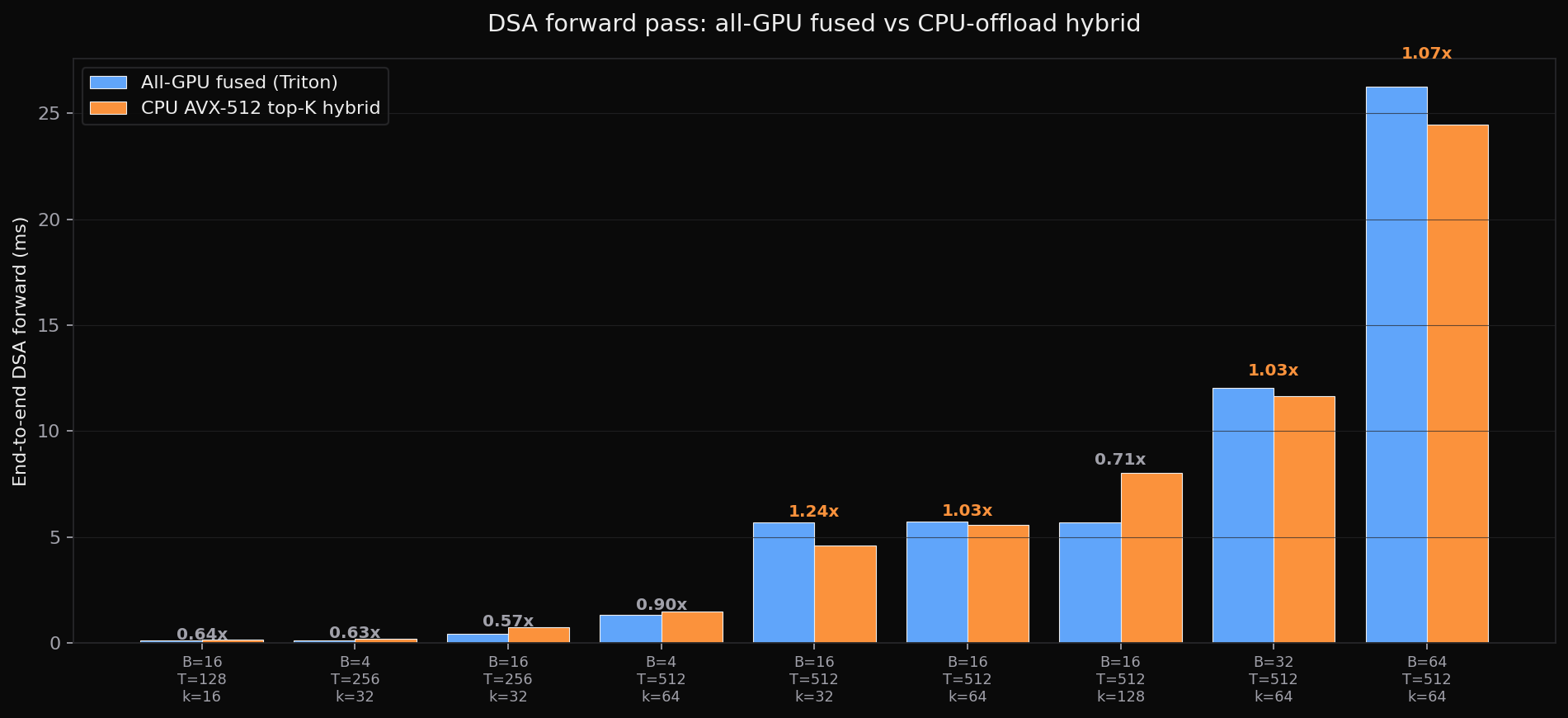
B T k | GPU fused (ms) CPU hybrid (ms) speedup
─────────────────────────────────────────────────────────
16 512 32 | 5.68 4.59 1.24x ← best
16 512 64 | 5.71 5.56 1.03x
32 512 64 | 12.03 11.65 1.03x
64 512 64 | 26.26 24.47 1.07x
16 512 128 | 5.69 8.02 0.71x k too big
4 512 64 | 1.34 1.48 0.90x B too small
16 128 16 | 0.10 0.16 0.64x T too small1.24× end-to-end at B=16, T=512, k=32 (5.68 ms → 4.59 ms). That's the headline. The hybrid wins in a specific regime: T large enough that the GPU bitonic sort over 512-element register tensors becomes the kernel's hot path, k small enough that CPU buffer-insertion stays cheap, B large enough to amortize per-launch fixed costs and PCIe setup. Outside that window - small T, large k, small B - the transfer overhead is just overhead.
Why this works at all
The all-GPU kernel keeps everything in registers per query program: indexer scores, the sort, the K/V tiles, the softmax. That's great until tl.sort of a length-T tensor starts dominating - bitonic sort has O(N log² N) shared work and at T=512 that's a lot of warp shuffles. Meanwhile the AVX-512 CPU version only really cares about the cheap path: read 16 floats, compare against threshold, decide. With 16 cores and a 96 MB V-Cache, mid-size score matrices fit comfortably.
PCIe 5.0 x16 pinned d2h sustains ~38 GB/s on this box. A 16 MB score matrix transfers in ~0.42 ms. That's the floor. The GPU's in-kernel sort cost has to exceed ~1-2 ms for the CPU offload to even be in the conversation. T=512 is roughly where that happens.
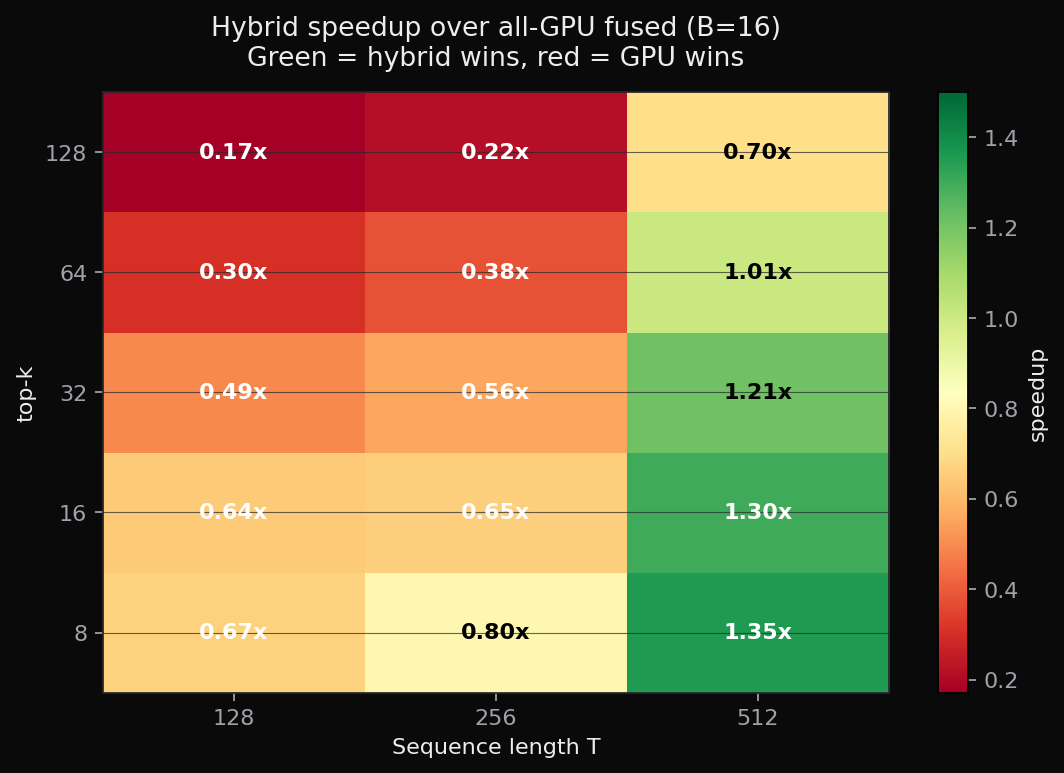
The heatmap makes the regime explicit. At B=16, the green band sits at T=512 with k ≤ 32. Move left (smaller T) and PCIe transfer dominates; move down-right (large k) and the CPU buffer-insertion cost dominates. There's exactly one corner where all the constants line up.
What changed after tuning
After the first result, I tried the obvious CPU-side optimizations: removing per-row heap allocation, specializing k=8/16/32, using a min-heap for k=64/128, batch-merging compressed candidates, binding OpenMP threads, pinning cores, and a small-k repeated-select path inside the Triton fused kernel. The changes that survived were the fixed small-k buffers, the large-k heap, and plain OMP_NUM_THREADS=16. Batch-merge was exact but slower, core pinning landed on busy cores, and the repeated-select GPU path did not beat tl.sort.
Clean run after heap/top-K tuning
B T k | GPU fused (ms) CPU hybrid (ms) speedup
─────────────────────────────────────────────────────────
16 512 32 | 5.74 4.60 1.25x
16 512 64 | 5.70 5.17 1.10x
64 512 64 | 26.26 22.78 1.15x
64 512 128 | 26.44 24.95 1.06xA larger scaling sweep
I also ran a wider wall-clock sweep across B ∈ {1,2,4,8,16,32,64}, T ∈ {64,128,256,512}, and valid k ∈ {8,16,32,64,128}. The x-axis below is B·T², the number of score-matrix elements the hybrid path has to compute, copy to CPU, threshold, and reuse on GPU. That is the scaling variable that matters most for this offload experiment.
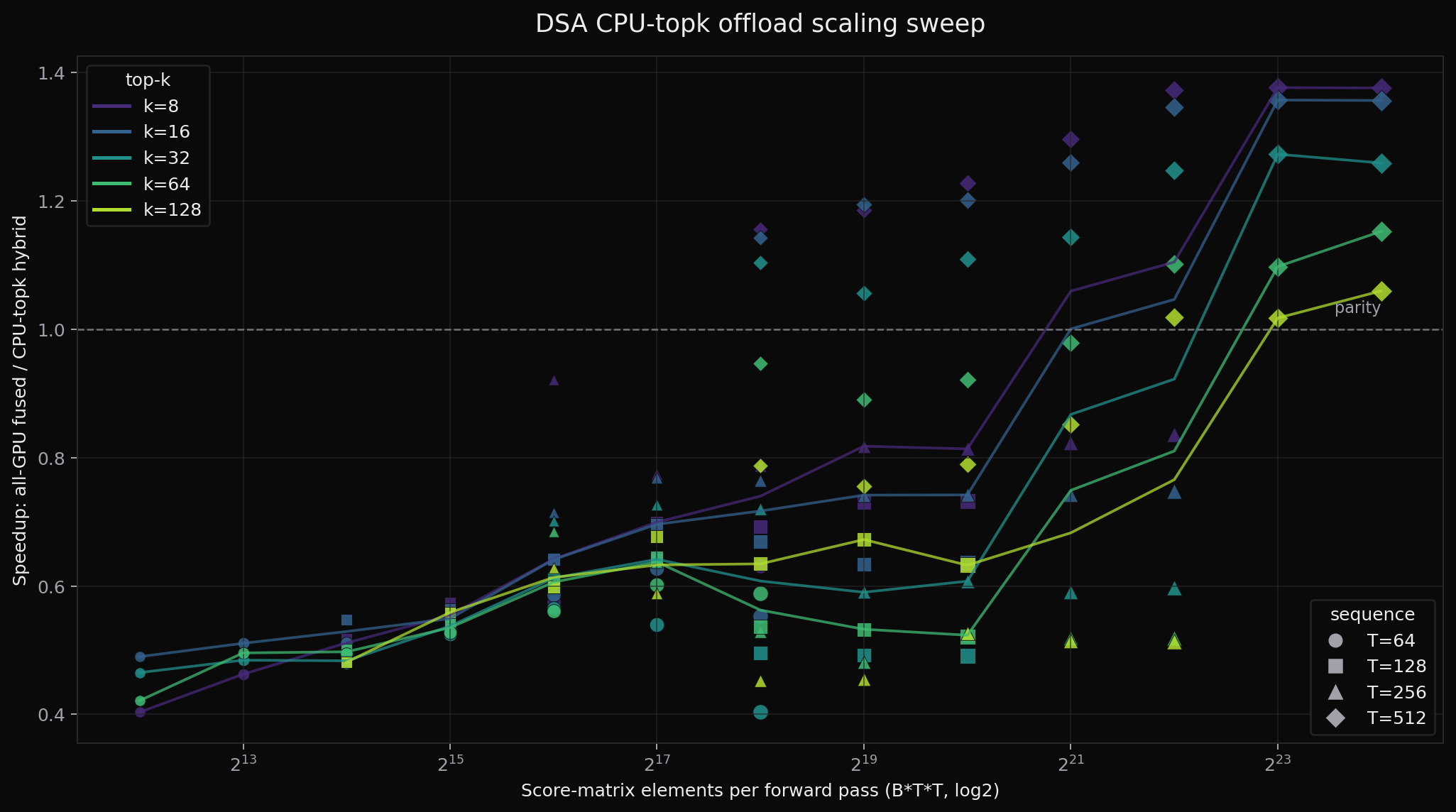
On an idle CPU with 16 OpenMP threads, the sweep shows 27 hybrid wins out of 133 configurations. The best point is 1.38× at B=32, T=512, k=8, and the T=512 band stays above parity for small and moderate k. The raw sweep data is available as scaling_sweep.csv.
What this is and isn't
This is not a production play. The honest fix for the GPU-fused kernel is to replace tl.sort with a radix-select or FAISS-style block-select. That would close the 1.2× gap without any CPU involvement and would scale past the T=512 register-pressure ceiling that the current fused kernel hits.
But as a single-machine experimental result the answer is yes: with the right primitive, mid-pipeline CPU offload can beat a naively-fused GPU kernel today. In this case the primitive is a narrow AVX-512 threshold kernel: vector scan, small-k sorted buffers, and a heap for larger k. The standard-library partial sort that PyTorch ships simply is not the right kernel for this workload.
Code
Full repo: github.com/Infatoshi/dsa-cpu-topk. The AVX-512 kernel is topk_avx512.cpp, the hybrid pipeline orchestrator is dsa_hybrid.py, and the headline table comes out of bench_hybrid.py. The DSA implementations (naive, vectorized PyTorch, fused Triton, and split Triton) live in dsa_attention.py with equivalence tests.
May 2026