GLM-4.7: Z.ai's Frontier Agentic Reasoning Model
A comprehensive technical analysis of GLM-4.7, the 358B parameter Mixture-of-Experts model pushing the boundaries of coding, reasoning, and agentic AI capabilities.
Executive Summary
GLM-4.7 represents Z.ai's latest iteration of their General Language Model series, building upon GLM-4.6 with substantial improvements across coding, reasoning, and tool-use benchmarks. Released under the MIT license, this model offers both cloud API access through Z.ai's platform and full local deployment options via HuggingFace.
Key highlights:
- 358 billion total parameters with 32 billion active parameters (Mixture-of-Experts)
- 200K context window for extensive document and code analysis
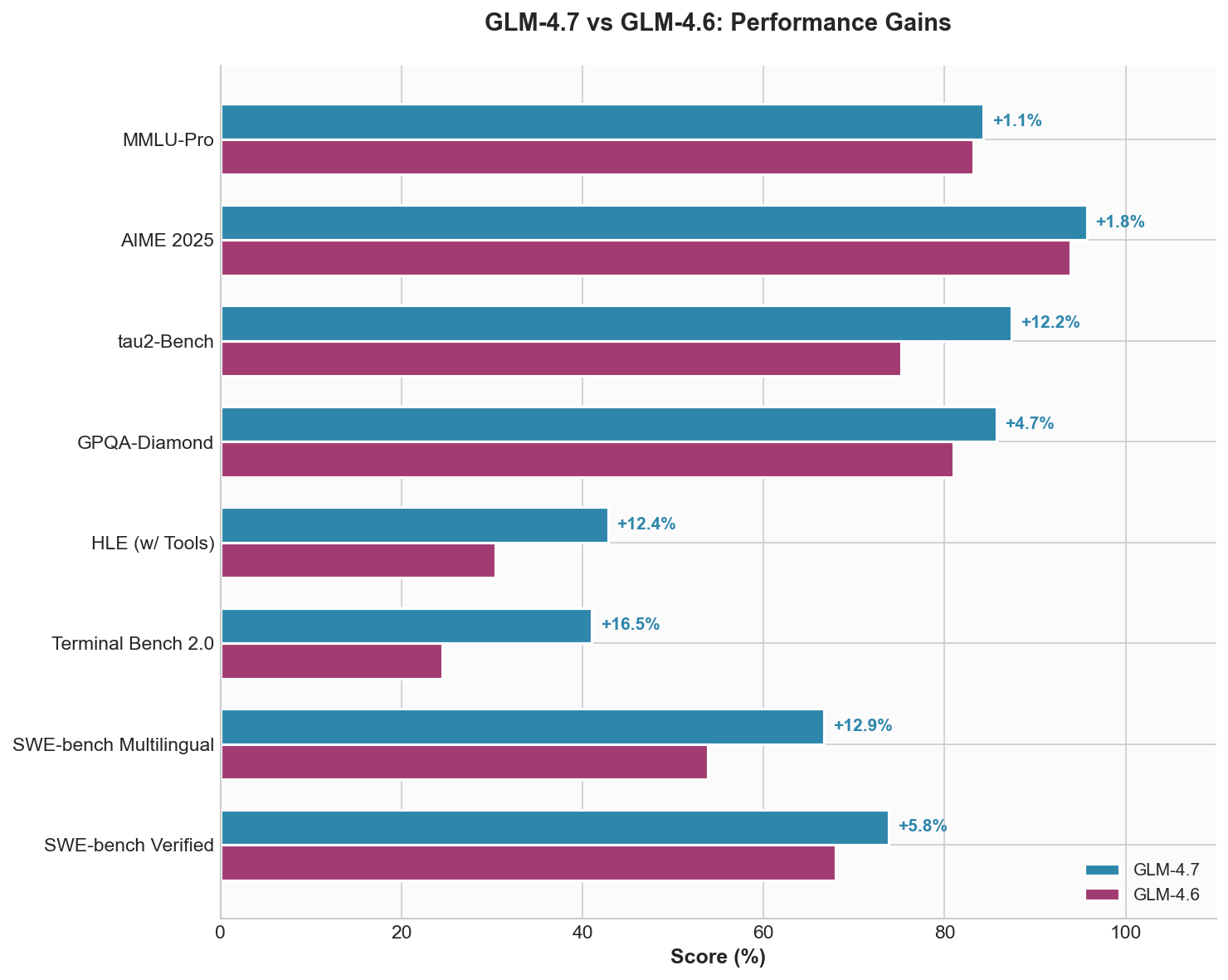
- 73.8% on SWE-bench Verified (+5.8% over GLM-4.6)
- 66.7% on SWE-bench Multilingual (+12.9% improvement)
- Three distinct thinking modes for flexible reasoning control
Model Architecture Deep Dive
GLM-4.7 employs a sophisticated Mixture-of-Experts (MoE) architecture that balances computational efficiency with model capacity. The architecture is designated as Glm4MoeForCausalLM in the HuggingFace ecosystem.

Core Transformer Configuration
| Parameter | Value | Description |
|---|---|---|
| Hidden Size | 5,120 | Dimensionality of hidden representations |
| Number of Layers | 92 | Total transformer blocks |
| Vocabulary Size | 151,552 | Token vocabulary including special tokens |
| Max Position Embeddings | 202,752 | Maximum sequence length (~200K tokens) |
Mixture-of-Experts Configuration
The MoE layer is the defining architectural feature of GLM-4.7:
| Parameter | Value | Description |
|---|---|---|
| Routed Experts | 160 | Total number of expert networks |
| Shared Experts | 1 | Always-active expert for common patterns |
| Experts Per Token | 8 | Active experts per forward pass |
| First K Dense Replace | 3 | First 3 layers use dense FFN (no MoE) |
Parameter calculation: Each token activates 8 out of 160 experts + 1 shared expert = 9 active experts. Active parameters: ~32B (8.9% of total capacity). Total parameters: ~358B. This sparsity ratio enables the model to maintain a massive knowledge capacity while keeping inference costs comparable to a ~32B dense model.
Thinking Modes
GLM-4.7 introduces a sophisticated thinking mode system designed for agentic coding workflows:
1. Interleaved Thinking
The model reasons before each response and before each tool call. This provides fine-grained reasoning that adapts to the current context, making it particularly useful for complex multi-step tasks.
2. Preserved Thinking
Reasoning blocks are maintained across multi-turn conversations, reducing redundant computation and maintaining coherent reasoning chains across tool calls.
3. Turn-level Thinking Control
Per-turn control allows lightweight requests to skip reasoning overhead entirely.
Benchmark Performance
Reasoning Benchmarks
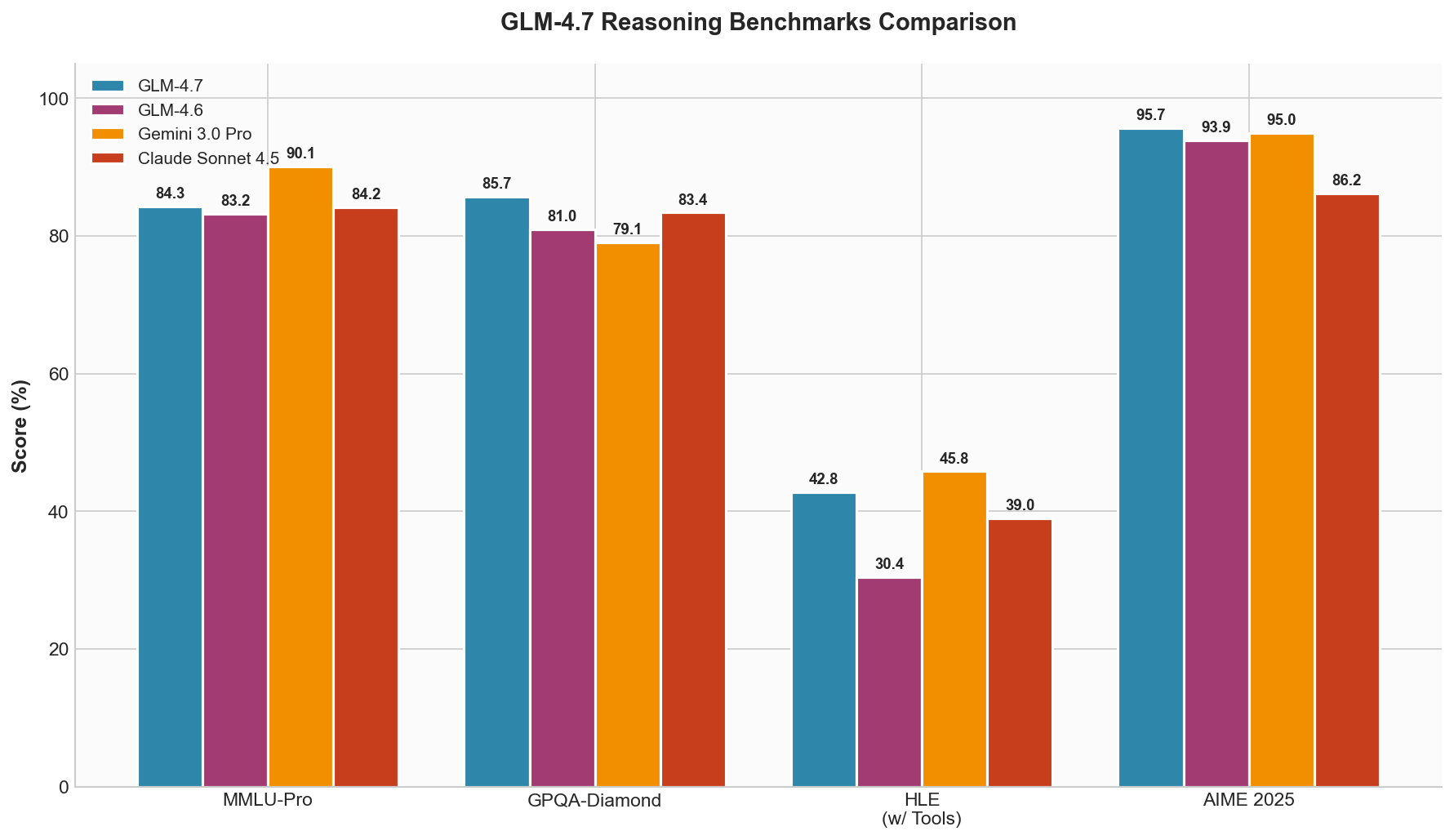
| Benchmark | GLM-4.7 | GLM-4.6 | Delta |
|---|---|---|---|
| MMLU-Pro | 84.3 | 83.2 | +1.1 |
| GPQA-Diamond | 85.7 | 81.0 | +4.7 |
| HLE (w/ Tools) | 42.8 | 30.4 | +12.4 |
| AIME 2025 | 95.7 | 93.9 | +1.8 |
Coding Benchmarks
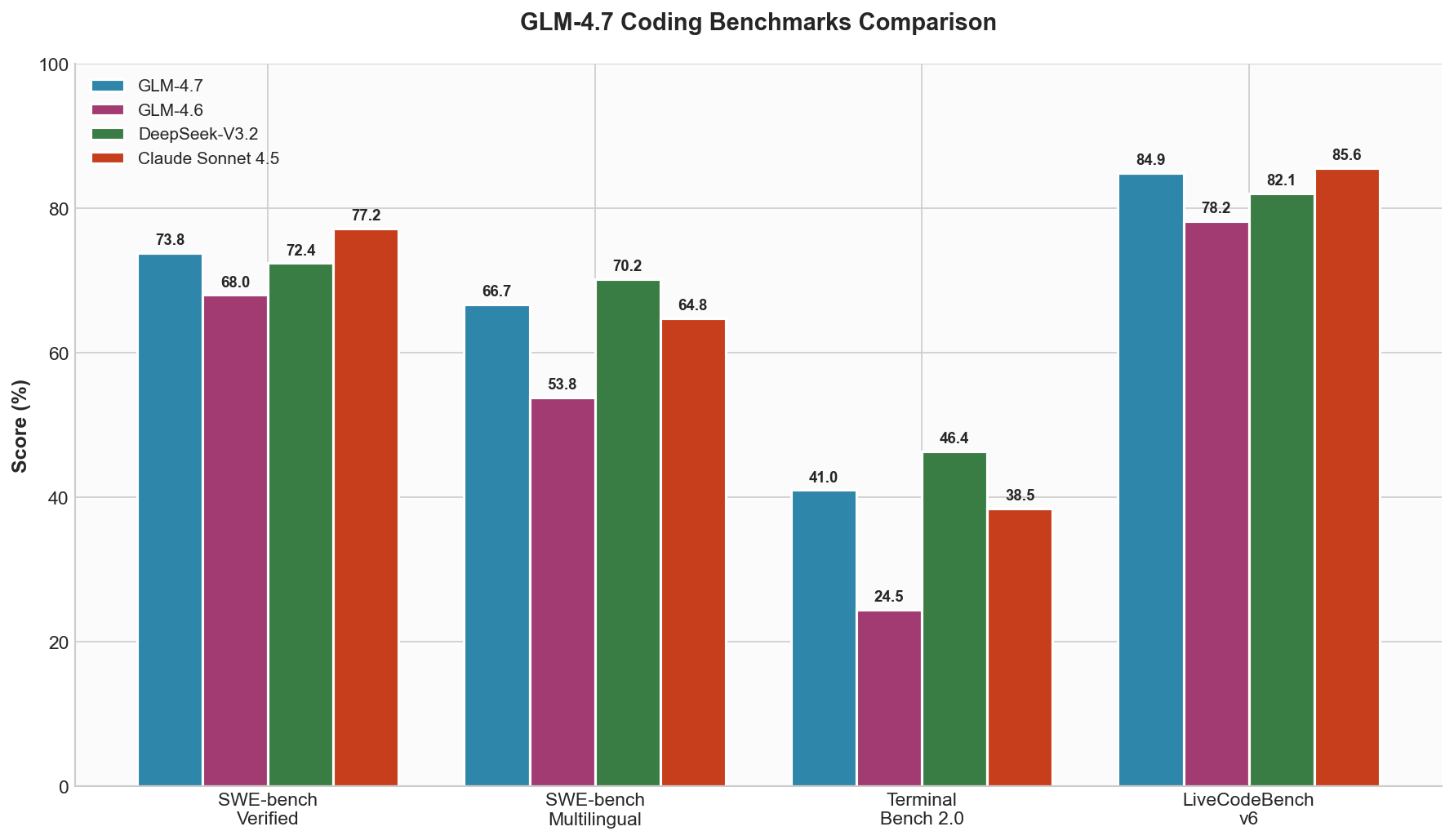
| Benchmark | GLM-4.7 | GLM-4.6 | Delta |
|---|---|---|---|
| SWE-bench Verified | 73.8 | 68.0 | +5.8 |
| SWE-bench Multilingual | 66.7 | 53.8 | +12.9 |
| Terminal Bench 2.0 | 41.0 | 24.5 | +16.5 |
| LiveCodeBench v6 | 84.9 | 78.2 | +6.7 |
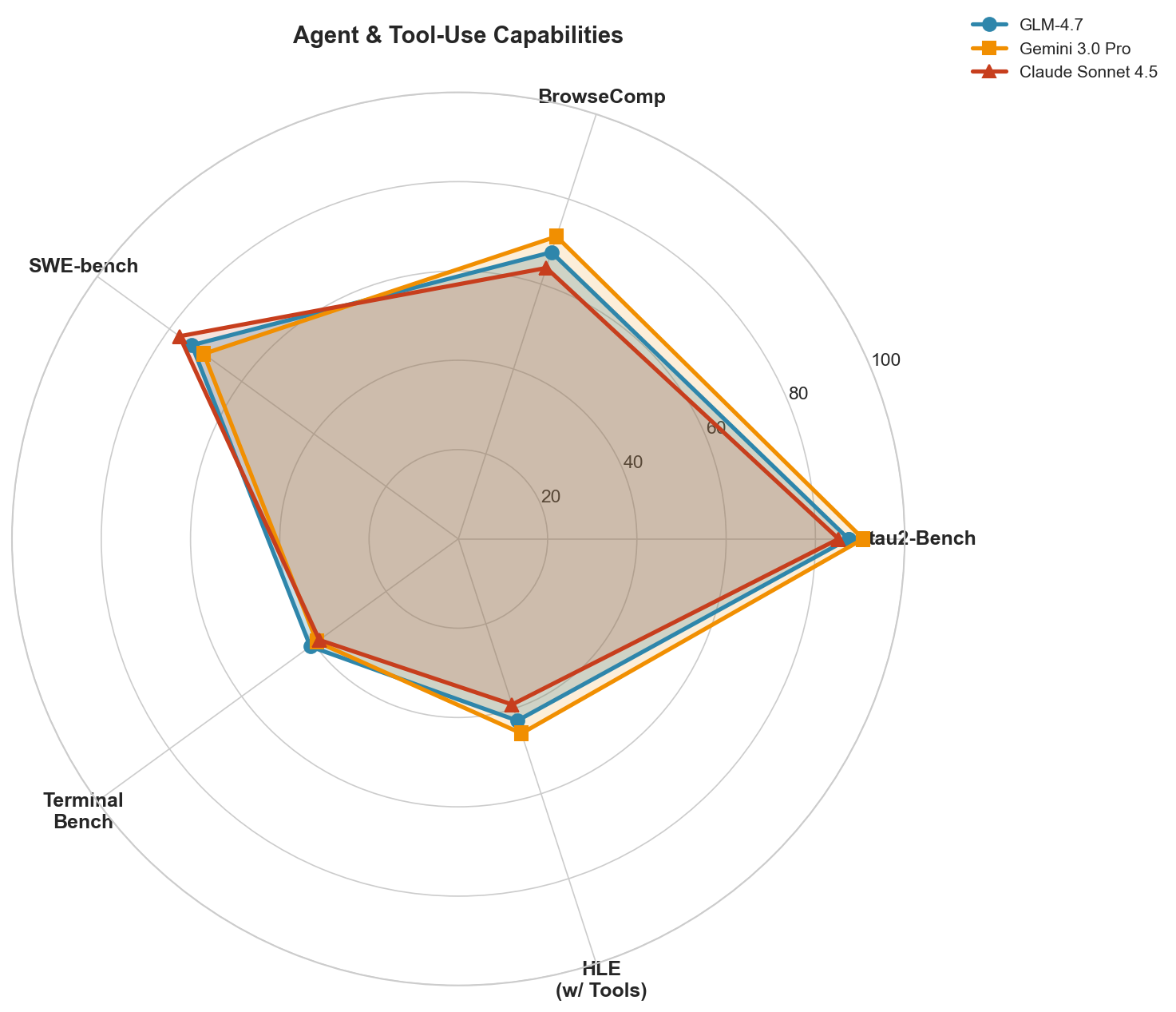
Agent and Tool-Use Benchmarks
Hardware Requirements
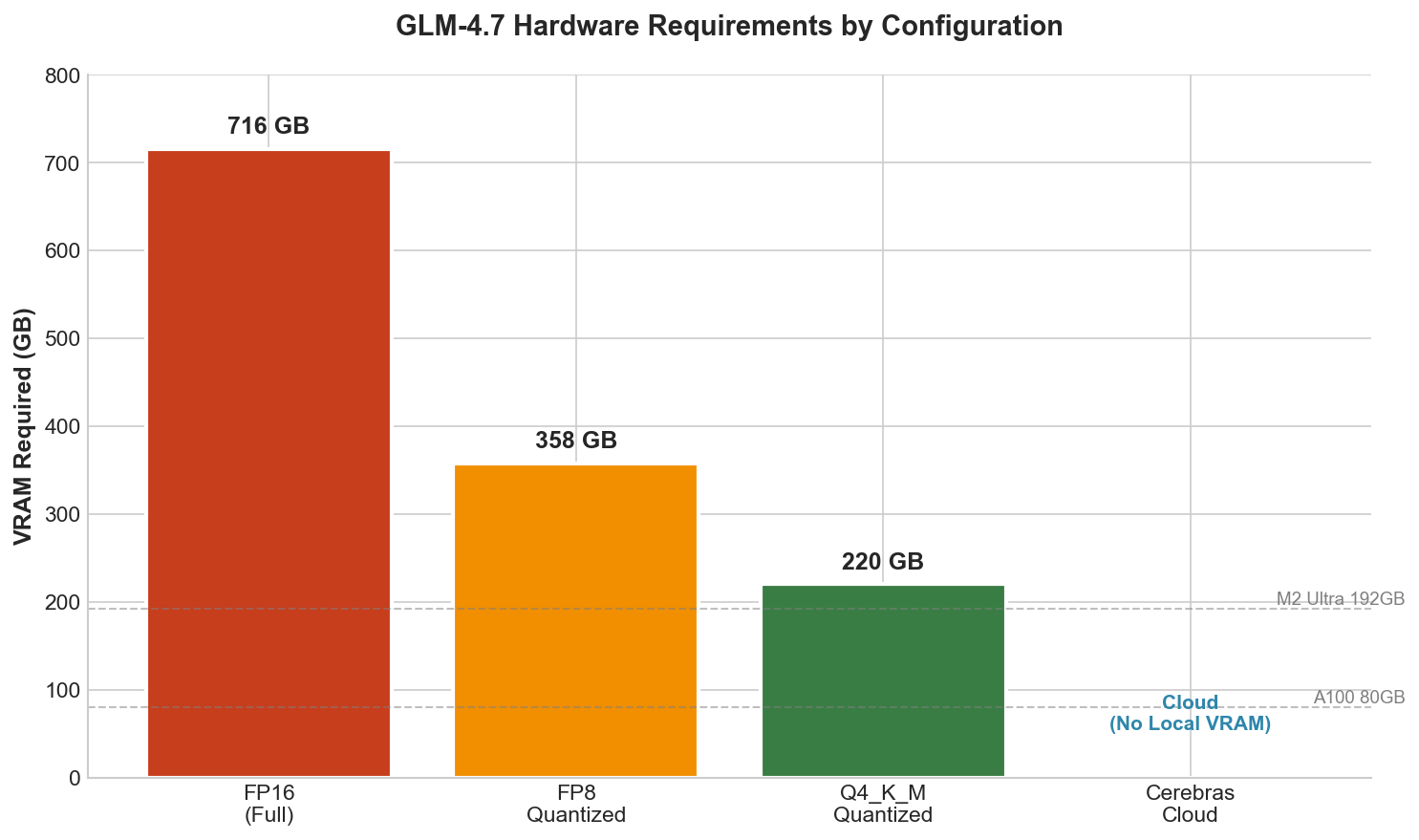
| Configuration | VRAM Required | Recommended Hardware |
|---|---|---|
| FP16 (Full Precision) | ~716 GB | 8x H100 80GB or equivalent |
| FP8 Quantized | ~358 GB | 4x H100 80GB |
| Q4_K_M Quantized | ~220 GB | High-end workstation (256GB+ unified memory) |
| Cloud (Z.ai/Cerebras) | N/A | API access, 1000+ tok/s |
Integration Ecosystem
GLM-4.7 integrates with major coding agents through Z.ai's Anthropic-compatible API:
- Claude Code - Anthropic's official CLI
- Kilo Code - VS Code extension
- Cline - AI coding assistant
- Roo Code - Cursor alternative
- OpenCode - Open-source coding agent
Technical Resources
Last updated: December 2025