MiniMax M2.1: The Open-Source Coding Powerhouse That Rivals Closed-Source Giants
Release Date: December 23, 2025 | Developer: MiniMax | Model Type: Sparse Mixture-of-Experts (MoE) Transformer
Executive Summary
MiniMax M2.1 represents a significant leap in open-source language model capabilities, particularly for software engineering and agentic workflows. Built on the foundation of MiniMax M2, this update delivers state-of-the-art performance in multilingual coding, agent scaffolding, and complex reasoning tasks - all while maintaining a fraction of the computational cost of competing closed-source models.
The model activates only 10 billion parameters per token from a total of 230 billion parameters, achieving what MiniMax calls "the most lightweight SOTA model" in its class.
Model Architecture
Mixture of Experts (MoE) Design
MiniMax M2.1 employs a sparse Mixture-of-Experts architecture - a design philosophy that prioritizes efficiency without sacrificing capability. Unlike dense transformers that activate all parameters for every token, MoE models selectively route tokens to specialized "expert" subnetworks.
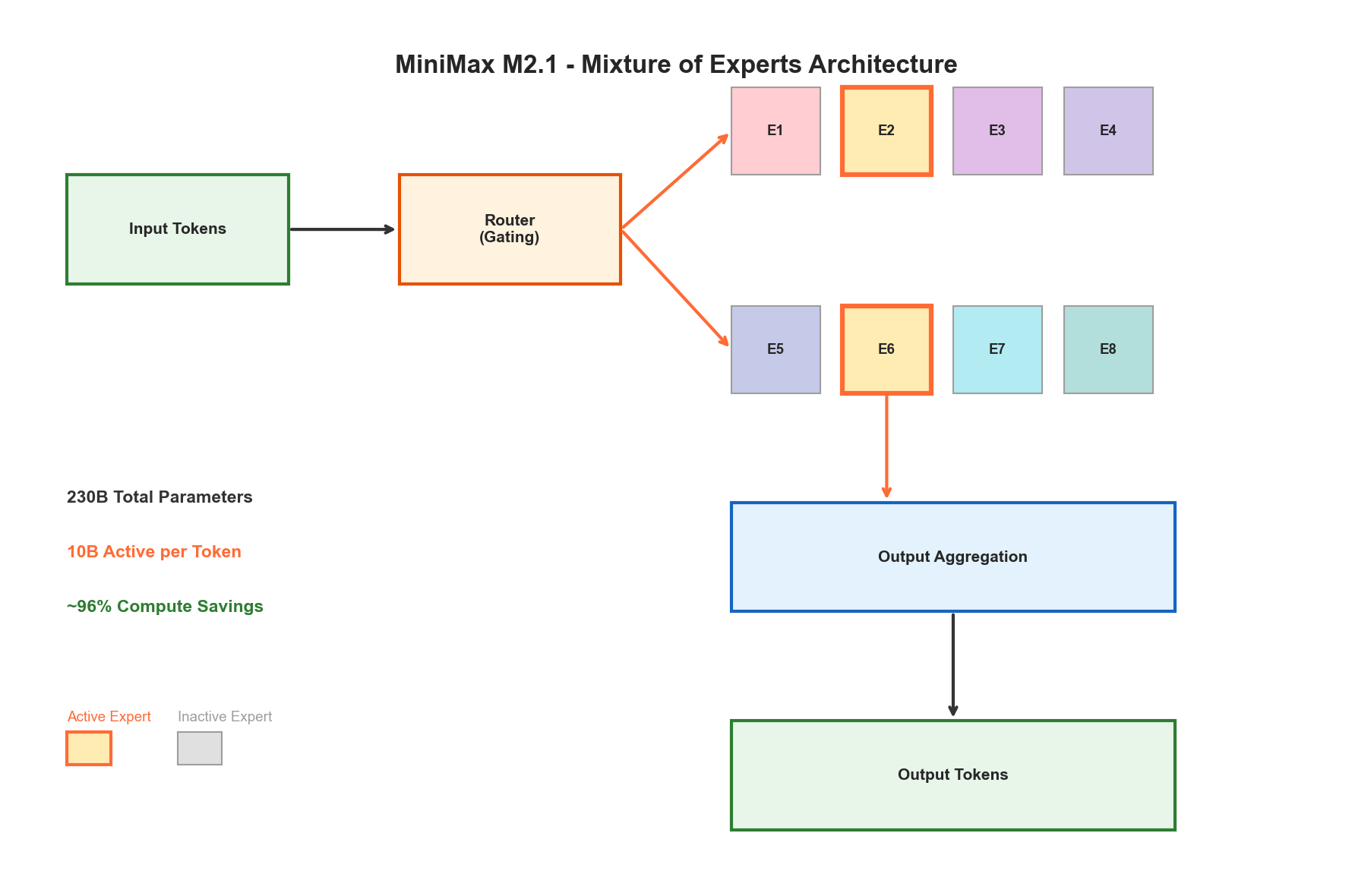
Key Architectural Specifications
| Specification | Value |
|---|---|
| Total Parameters | 230 billion |
| Active Parameters (per token) | 10 billion |
| Activation Ratio | ~4.3% |
| Context Length (Input) | 128,000 - 204,800 tokens |
| Max Output Tokens | 131,072 tokens |
| Architecture Type | Sparse MoE Transformer |
The sparse activation pattern yields approximately 96% compute savings compared to a hypothetical dense model of equivalent total capacity. According to Artificial Analysis, the model can be served efficiently on as few as four NVIDIA H100 GPUs at FP8 precision - a setup accessible to mid-size organizations.
Interleaved Thinking: Beyond Linear Chain-of-Thought
One of M2.1's defining innovations is its Interleaved Thinking capability. Rather than following a linear Chain-of-Thought (CoT) process, the model implements a dynamic Plan - Act - Reflect loop:
- Plan: Formulate an approach based on current context
- Act: Execute tool calls or generate outputs
- Reflect: Evaluate results and adjust strategy in real-time
This architecture enables real-time self-correction when tool outputs diverge from initial plans, state preservation across reasoning steps, and extended horizon handling for complex agentic workflows.
MiniMax describes M2.1 as "one of the first open-source model series to systematically introduce Interleaved Thinking," with benchmarks showing a +3% improvement on SWE-Bench Verified and a remarkable +40% improvement on BrowseComp when interleaved thinking is enabled.
Benchmark Performance
SWE-bench Verified: Software Engineering Tasks
The SWE-bench Verified benchmark evaluates models on real-world software engineering tasks requiring multi-file edits and test validation.
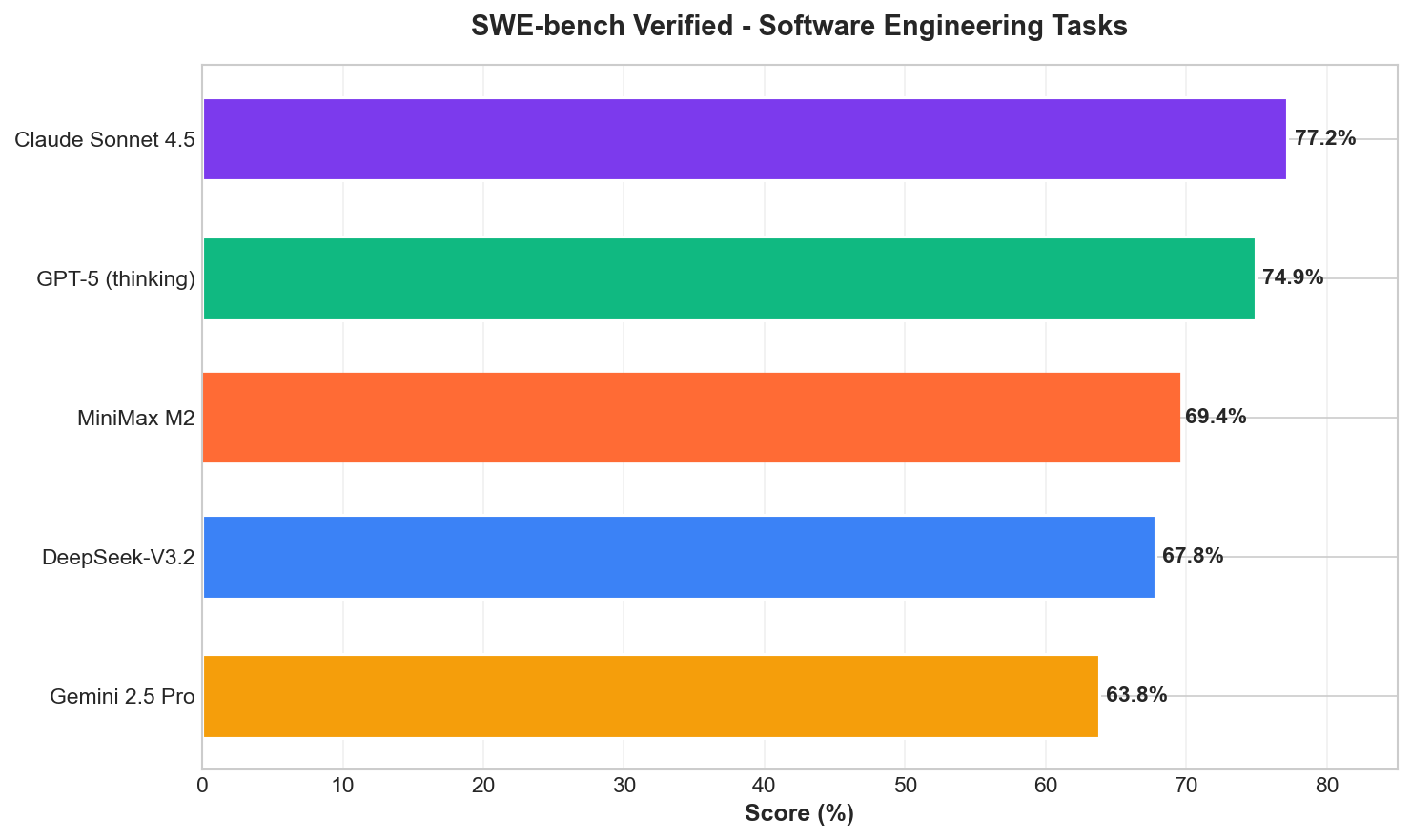
M2.1 Specific Results:
- Multi-SWE-Bench: 49.4% (surpassing Claude 3.5 Sonnet and Gemini 1.5 Pro)
- SWE-bench Multilingual: 72.5%
- SWE-bench Verified (M2): 69.4%
- SWE-bench Verified (M2.1): 74.0%
Tau-2 Bench: Agentic Tool Use
This benchmark tests models on complex tool-calling scenarios - a critical capability for coding assistants and autonomous agents.
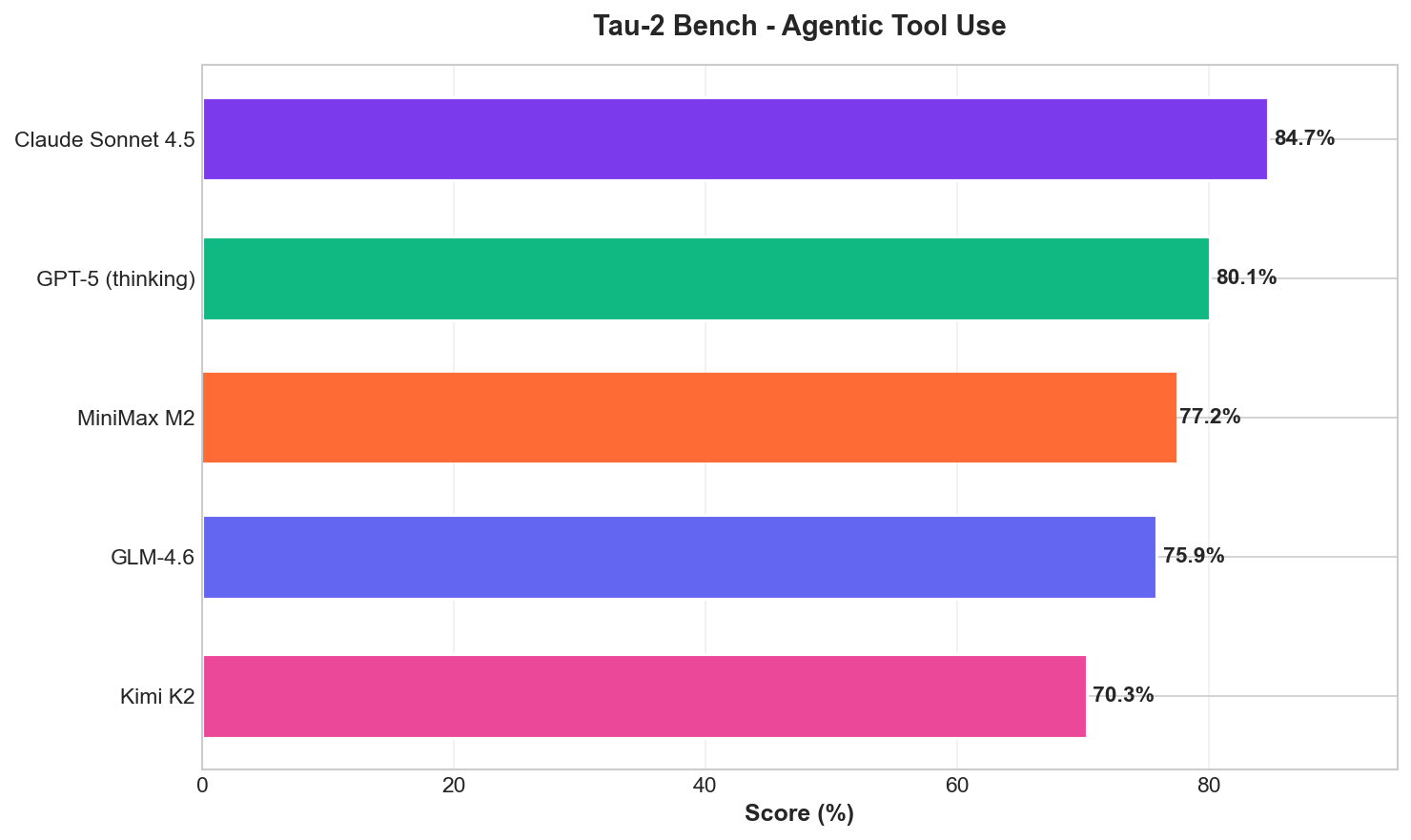
MiniMax M2 scores 77.2%, placing it ahead of GLM-4.6 (75.9%) and Kimi K2 (70.3%), though behind Claude Sonnet 4.5 (84.7%).
IFBench: Instruction Following
Perhaps M2's most impressive showing comes on IFBench, which tests precise instruction adherence:
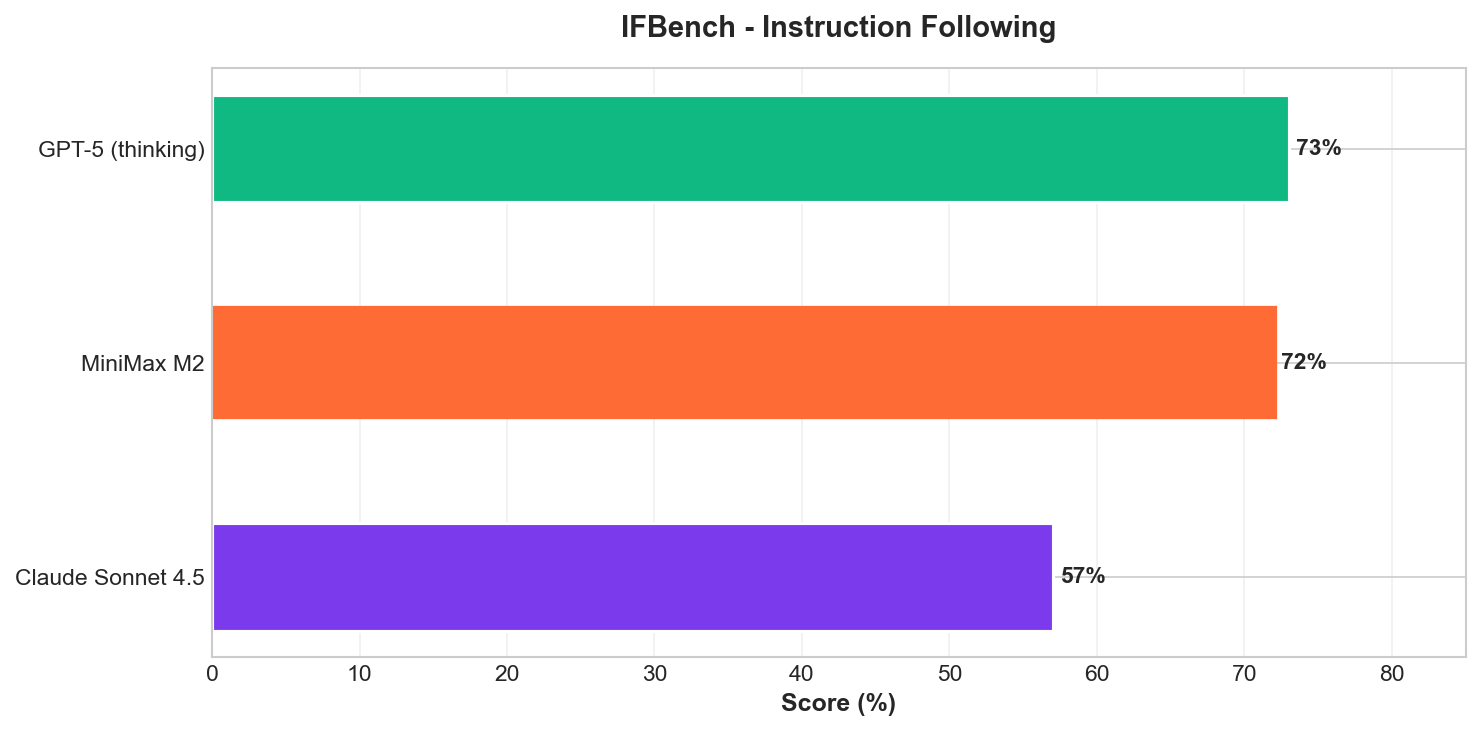
MiniMax M2 achieves 72%, significantly outperforming Claude Sonnet 4.5 (57%) while narrowly trailing GPT-5 with thinking (73%). This result highlights M2's strength in understanding and executing complex, multi-constraint instructions.
Terminal-Bench: Command-Line Execution
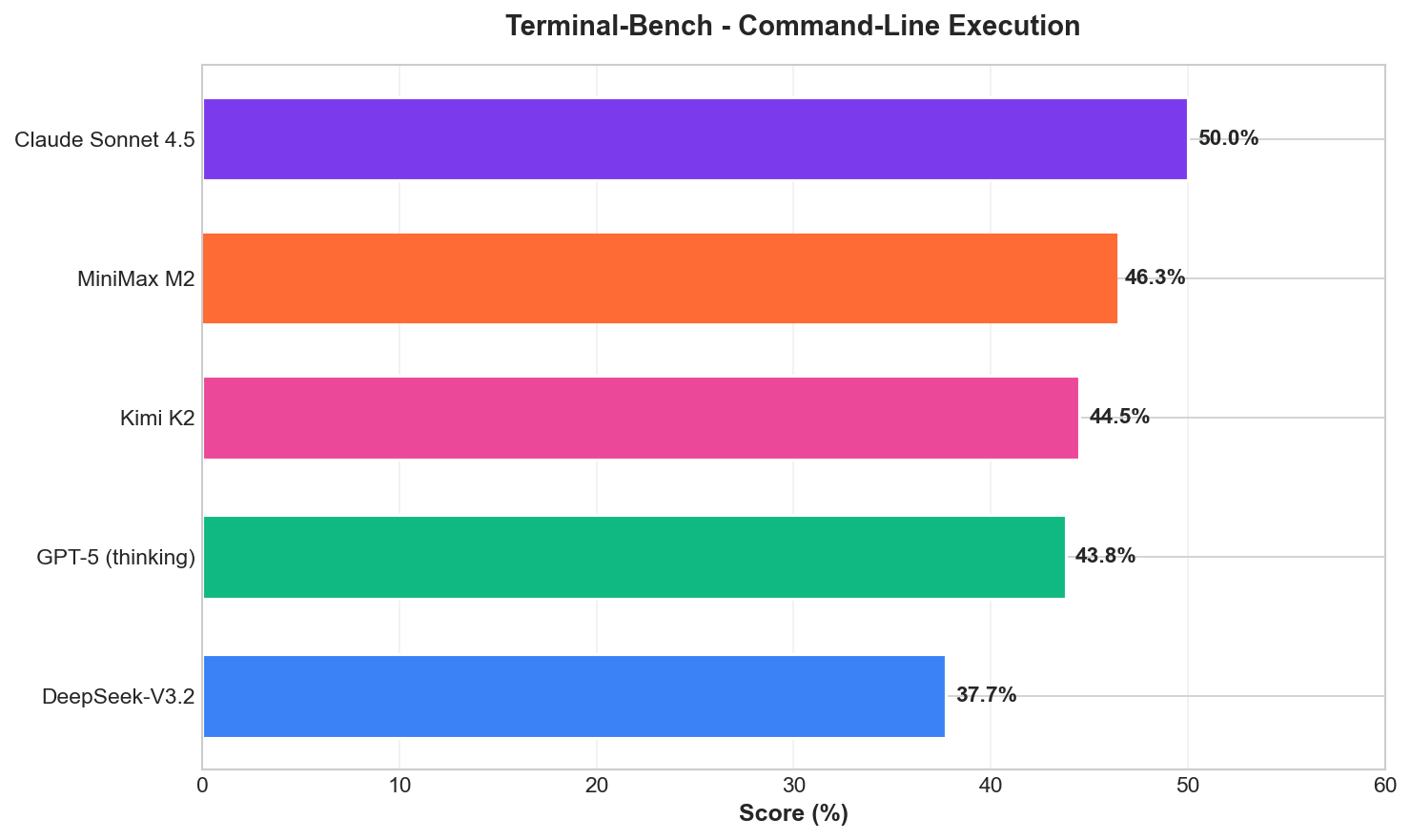
MiniMax M2 places second at 46.3%, just behind Claude Sonnet 4.5 (50%) and ahead of GPT-5 with thinking (43.8%).
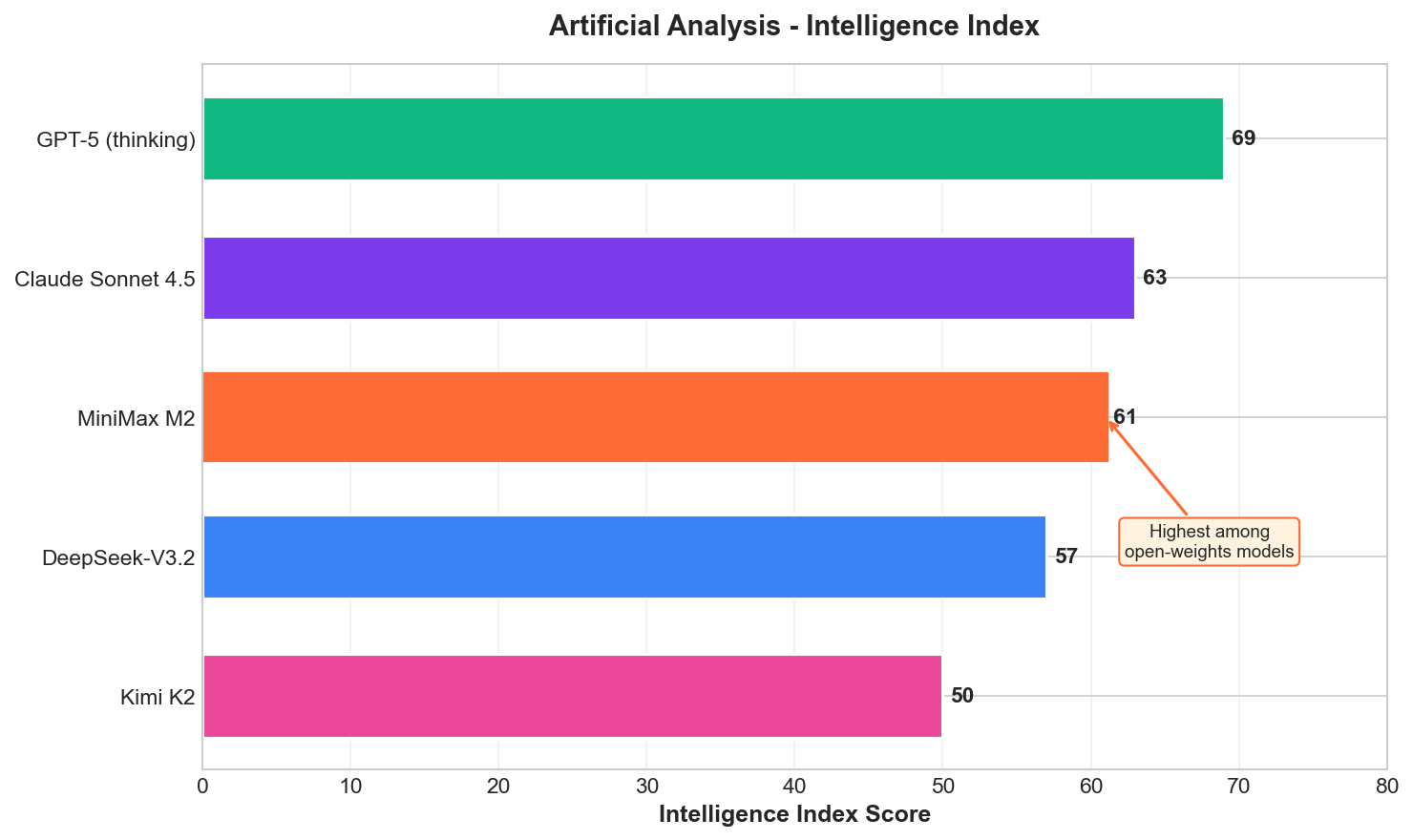
Intelligence Index
Artificial Analysis ranks MiniMax M2 with an Intelligence Index of 61 - the highest among all open-weights models:
M2.1 Specific Benchmarks
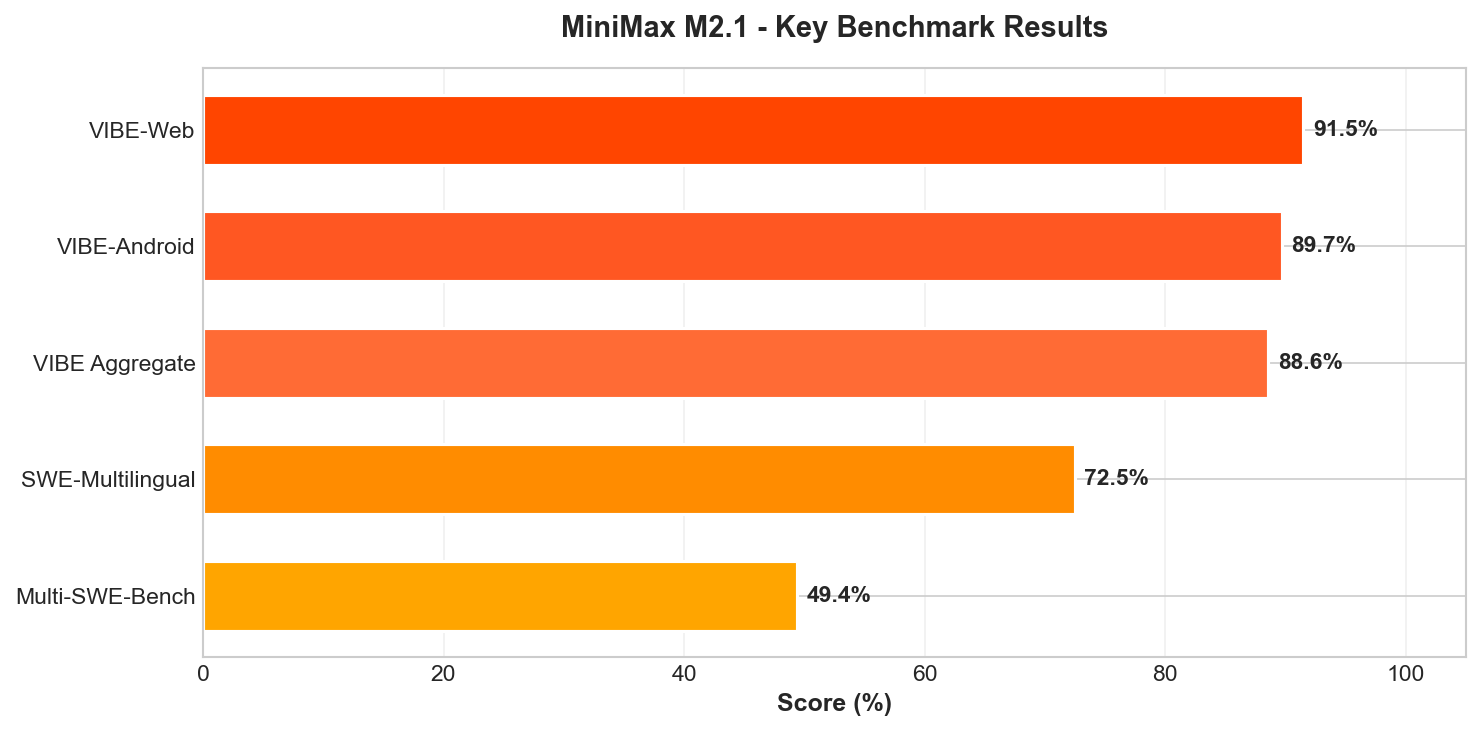
| Benchmark | Score |
|---|---|
| VIBE-Web | 91.5% |
| VIBE-Android | 89.7% |
| VIBE Aggregate | 88.6% |
| SWE-Multilingual | 72.5% |
| Multi-SWE-Bench | 49.4% |
Multilingual Programming Support
MiniMax M2.1 demonstrates exceptional capabilities across diverse programming languages and domains:
Supported Languages:
- Rust, Java, Golang, C++
- Kotlin, Objective-C
- TypeScript, JavaScript
Specialized Domains:
- Web3 and blockchain protocols
- Native mobile development (Android and iOS)
- Code review and performance optimization
- Test case generation
In multilingual scenarios, M2.1 outperforms Claude Sonnet 4.5 and closely approaches Claude Opus 4.5 levels of capability.
Cost Analysis
One of M2.1's most compelling value propositions is its pricing - approximately 10% of Claude Sonnet's cost with comparable or superior performance in many benchmarks.
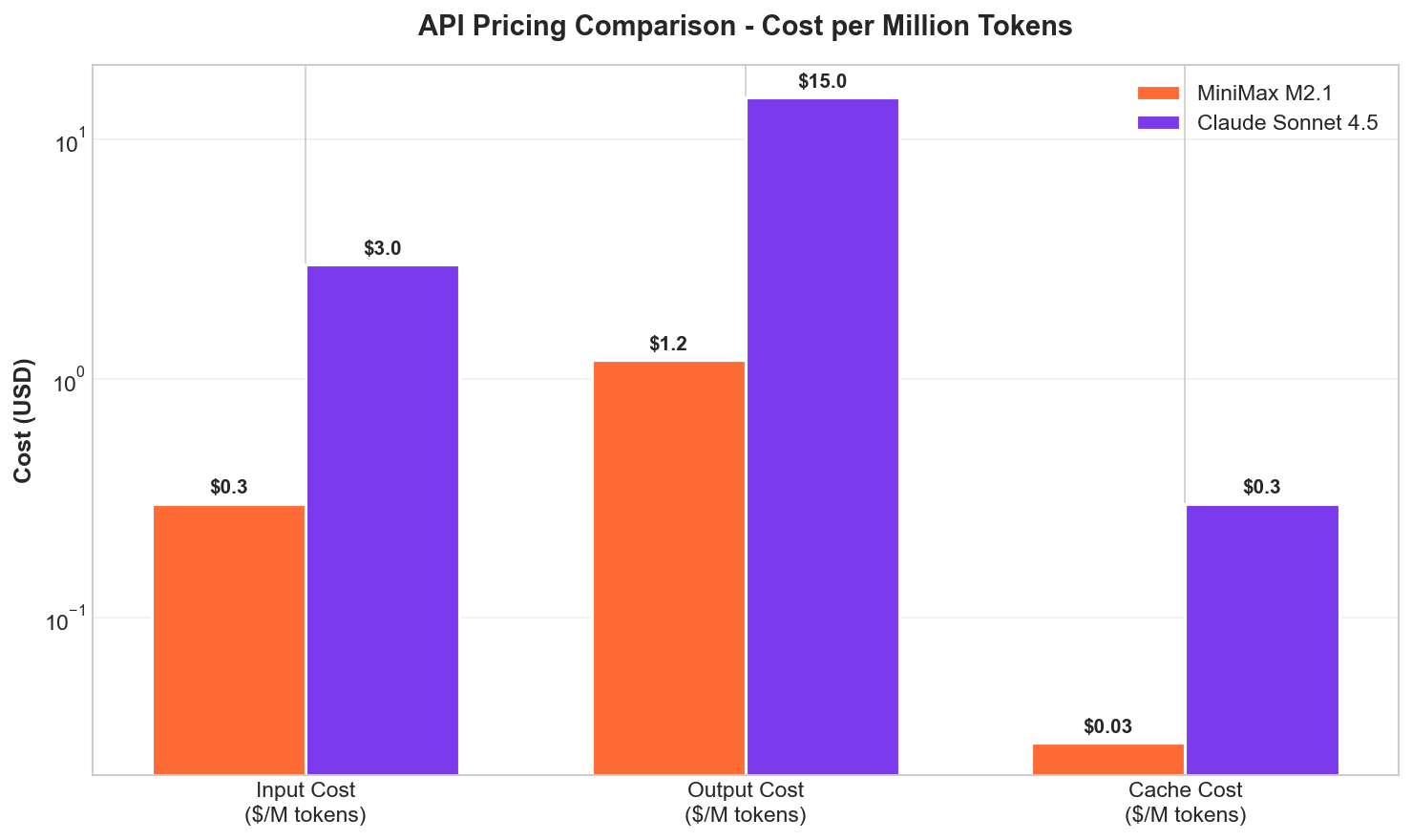
Pricing (via OpenRouter)
| Token Type | MiniMax M2.1 | Claude Sonnet 4.5 | Savings |
|---|---|---|---|
| Input | $0.30/M | ~$3.00/M | 90% |
| Output | $1.20/M | ~$15.00/M | 92% |
| Cache Hits | $0.03/M | ~$0.30/M | 90% |
This pricing makes M2.1 particularly attractive for high-volume agentic workflows, CI/CD integration with automated code review, development teams with budget constraints, and research and experimentation.
Platform Integration
M2.1 natively integrates with popular coding assistant frameworks:
- Claude Code
- Cursor
- Cline
- Kilo Code
- Droid
- Roo Code
Conclusion
MiniMax M2.1 represents a significant milestone in open-source AI development. By combining a sparse MoE architecture with innovative Interleaved Thinking capabilities, MiniMax has created a model that:
- Matches or exceeds closed-source competitors in instruction following (IFBench)
- Approaches SOTA on software engineering benchmarks
- Costs 90% less than comparable proprietary alternatives
- Runs efficiently on accessible hardware configurations
For development teams seeking a powerful, cost-effective coding assistant with open weights, M2.1 presents a compelling option. Its multilingual strength, agentic capabilities, and transparent architecture make it particularly valuable for organizations that require customization or self-hosting.
The model's release signals an accelerating trend: open-source models are no longer playing catch-up - they are competing directly with, and in some cases surpassing, their closed-source counterparts.
Last updated: December 23, 2025